Time series
See also: Time series modeling in finance, Time series in ModelRisk, Autoregressive models, Geometric Brownian Motion models, Markov Chain models, Birth and death models
Introduction
Time series projections are used to model variables like import volumes, outbreak numbers, consumption rates, share price, exchange rates and bacterial growth where we are interested in modeling the variable over more than one period. We model these variables over time because it is important to us to know their values at intermediate stages in the history of the variable, not just at one point in time.
For the use and implementation of time series models in ModelRisk, see the Time series in ModelRisk topic.
The time series models that we produce must reflect:
- The relationship of the variable's value at each modelled period;
- Realistic ranges of the variable with time;
- Any trends (drift), seasonality, and cyclicity (identifiable, non-periodic event)
- The relationship between uncertainty and time (whether it increase or decreases, for example)
The simplest forecasting technique is to use the last value available in a time series as our estimate of all future values. This naive forecast is useful because we can look at the forecasting errors it produces and compare those errors with the errors produced by the other more sophisticated techniques. Clearly, if a more sophisticated and time-consuming technique does not provide us with an appreciable increase in accuracy over the naive forecast, it will not be worth adopting. We should attempt to find the technique that produces the smallest forecasting error for the least effort as our best estimator of the future.
The naive forecast may seem over-simplistic, but it is the most appropriate single point estimate of all methods if the parameter being estimated varies according to a random walk. The simplest random walk is where the (n+1)th term in a series is equal to the nth term plus a movement that has a symmetric, zero-centred probability distribution. Such a series has no memory of the path it took to arrive at the nth value: thus, no seasonal or cyclical patterns or trends exist except by pure chance. There are several other types of random walks, and we will look at some of the most important ones.
A notational convention
We use the following convention for describing a time series: St is the value of the time series variable at time t. Thus, for example, a random walk might be expressed as:
St=St-1*Uniform(0.9,1.1)
This means that the variable S at time t is only dependent on its value in the previous period (t-1), and is between 90% and 110% of its previous value.
Some useful principles
- The model's behavior can be checked with imbedded Excel x-y scatter plots;
- Split the model up into components rather than create long, complicated formulae. That way you'll see that each component is working correctly, and therefore have confidence in the time series projection as a whole;
- Be realistic about the match between historic patterns and projections. Don't always go for a forecast model because it fits the data the best - also look at whether there is a logical reason for choosing one model over another;
- Be creative. Short-term forecasts (say 20-30% of the historic period for which you have good data) are often adequately produced from a statistical analysis of your data. Even then, be selective about the model. However, beyond that time frame we move into crystal ball gazing. Including your perceptions of where the future may go, possible influencing events, etc will be just as valid as an extrapolation of historic data.
The properties of a time series forecast
When producing a risk analysis model that forecasts some variable over time I recommend you go through a list of several properties that variable might exhibit over time as this will help you both statistically analyze any past data you have and select the most appropriate model to use. The properties are: trend, randomness, seasonality, cyclicity or shocks, and constraints.
Trend
Most modeled variables have a general direction - a trend - in which they have been moving, or we believe they will move in the future. The four plots below give some examples of the expected value of a variable over time: top left - a steady relative decrease, such as one might expect for sales of an old technology, number of individuals remaining alive from a group; top right - a steady (straight line) increase, such as is often assumed for financial returns over a reasonably short period (sometimes called 'drift'); bottom left - a steady relative increase, such a bacterial growth or take up of new technology; and bottom right - a drop turning into an increase, such as the rate of component failures over time (like the bathtub curve in reliability modelling) or advertising expenditure (more at a launch, then lower, then ramping up to offset reduced sales).
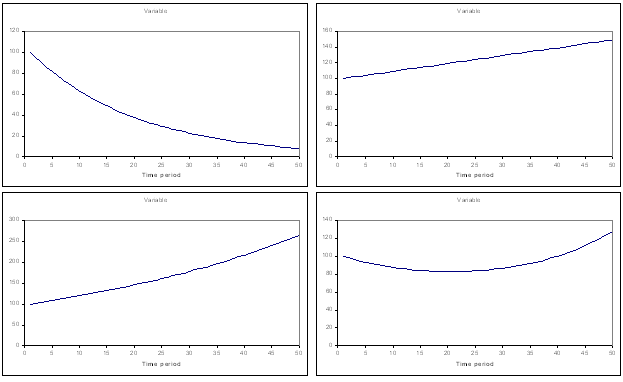
Examples of expected value trend over time
Randomness
The second most important property is randomness. The four plots below give some examples of the different types of randomness: top left - a relatively small and constant level of randomness that doesn't hide the underlying trend ; top right - a relatively large and constant level of randomness that can disguise the underlying trend; bottom left - a steadily increasing randomness, which one typically sees in forecasting (care needs to be taken to ensure that the extreme values don't become unrealistic); and bottom right - levels of randomness that vary seasonally.
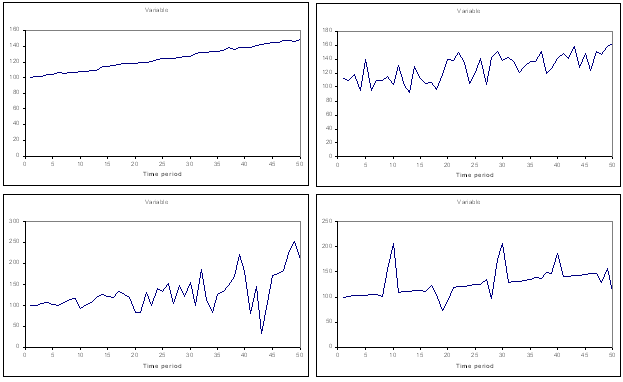
Examples of the behavior of randomness over time
Seasonality
Seasonality means a consistent pattern of variation of the expected value (but also sometimes its randomness) of the variable. There can be several overlaying seasonal periods but we should usually have a pretty good guess at what the periods of seasonality might be: hour of the day; day of the week; time of the year (summer/winter, for example, or holidays, or end of financial year). The following plot shows the effect of two overlaying seasonal periods. The first is weekly with a period of 7, the second is monthly with a period of 30, which complicates the pattern. Monthly seasonality often occurs with financial transactions that occur on a certain day of the month: for example, volumes of documents that a bank's printing facility must produce each day - at the end of the month they have to churn out bank and credit card statements and get them in the post within some legally defined time.
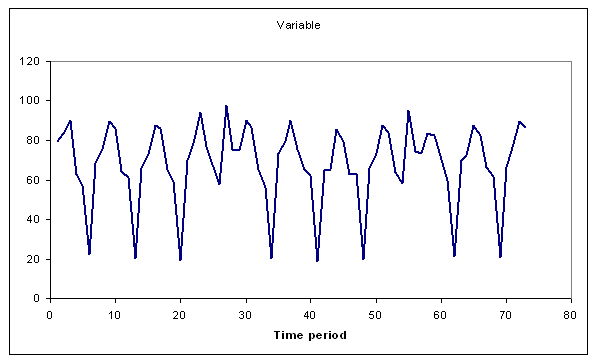
Expected value of a variable with two overlapping seasonal periods.
One difficulty in analyzing monthly seasonality from data is that months have different lengths, so one cannot simply investigate a difference each 30 days, say. Another hurdle in analyzing data on variables with monthly and holiday peaks is that there can be some spread of the effect over two or three days.
For example, we performed an analysis recently looking at the calls received into a US insurance company's national call centre to help them optimize how to staff the centre. We were asked to produce a model that predicted every 15 minutes for the next two weeks, and another model to predict out six weeks. We looked at the patterns by individual state and language (Spanish and English). There was a very obvious and stable pattern through the day that was constant during the working week, but had a different pattern on Saturday and on Sunday. The pattern was largely the same between states but different between languages. Holidays like Thanksgiving (the last Thursday of November, so not even a fixed date) were very interesting: call rates dropped hugely on the holiday to 10% of the level one would have usually expected, but were slightly lower than normal the day before (Wednesday), significantly lower the day after (Friday), a little lower during the following weekend, and then significantly higher the following Monday and Tuesday (presumably because people were catching up on calls they needed to make). Memorial Day, the last Monday of May, exhibited a similar pattern, as shown in the figure below.
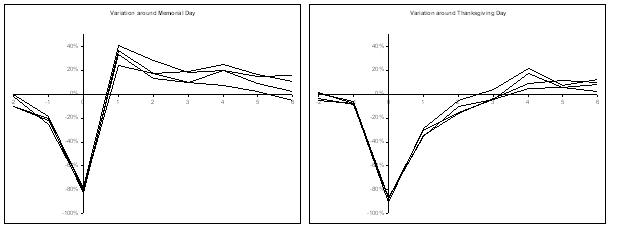
Effect of holidays on daily calls to a call centre. The four lines show the effect on last four years.
Zero on the x-axis is the day of the holiday
The final models had logic built into them to look for forthcoming holidays and apply these patterns to forecast expected levels which had a trend by state and a daily seasonality. For the 15-minute models we also had to take into account the time zone of the state, since all calls from around the US were received into one location, which also involved thinking about when states changed their clocks from summer to winter and little peculiarities like some states having two time zones, Arizona doesn't observe daylight saving to conserve energy used by air-conditioners, etc.).
Cyclicity or shocks
Cyclicity is a confusing (rather similar to seasonality) term that refers to the effect of obvious single events on the variable being modelled. For example, the Hatfield rail crash in the UK on 12 October 2000 was a single event with a long-term effect on the UK railway network. The accident was caused by the lapsed maintenance of the track which led to 'gauge corner cracking', resulting in the rail separating. Investigators found many more such cracks in the area and a temporary speed restriction was imposed over very large lengths of track because of fears that other track might be suffering from the same degradation. The UK network was already at capacity levels so slowing down trains resulted in huge delays. The cost of repairs to the under-maintained track also sent RailTrack, the company managing the network, into administration. In analyzing the cause of train delays for our client, NetworkRail, a not-for-dividend company that took over from RailTrack, we had to estimate and remove the persistent effect of Hatfield.
Another obvious example is 9/11. Anyone who regularly flies on commercial airlines will have experienced the extra delays and security checks. The airline industry was also greatly affected, with several US carriers filing for protection under Chapter 11, though other factors also played a part like oil price increases and other terrorist attacks (also cyclicity events) which dissuaded people from going abroad. We performed a study to determine what price should be charged for parking at a US national airport, part of which included estimating future demand. Analyzing historic data, it was evident that the effect of 9/11 on passenger levels was quite immediate and as of 2006 was only just returning to 2000 levels, where previously there had been consistent growth in passenger numbers so levels still remain far below what would have been predicted before the terrorist attack.
Events like Hatfield and 9/11 are, of course, almost impossible to predict with any confidence. However, other types of cyclicity events are more predictable. As I write this (20 June, 2007), there are seven days left before Tony Blair steps down as Prime Minister of the UK which he announced on 10 May, and Gordon Brown takes over. Newspapers columnists are debating what changes will come about and, for people in the know, there are probably some predictable elements.

Two examples of the effect of a cyclicity shock. On the left, the shock produces a sudden and sustained increase of the variable; on the right the shock produces a sudden increase that gradually reduces over time - an exponential distribution is often used to model this reduction.
Constraints
Randomly varying time series projections can quite easily produce extreme values far beyond the range that the variable might realistically take. There are a number of ways to constrain a model. Mean reversion discussed later will pull a variable back to its mean so that it is far less likely to produce extreme values. Simple logical bounds like IF(St>100,100,St) will constrain a variable to remain at or below 100, and one can make the constraining parameter (100) a function of time too.
Navigation
- Risk management
- Risk management introduction
- What are risks and opportunities?
- Planning a risk analysis
- Clearly stating risk management questions
- Evaluating risk management options
- Introduction to risk analysis
- The quality of a risk analysis
- Using risk analysis to make better decisions
- Explaining a models assumptions
- Statistical descriptions of model outputs
- Simulation Statistical Results
- Preparing a risk analysis report
- Graphical descriptions of model outputs
- Presenting and using results introduction
- Statistical descriptions of model results
- Mean deviation (MD)
- Range
- Semi-variance and semi-standard deviation
- Kurtosis (K)
- Mean
- Skewness (S)
- Conditional mean
- Custom simulation statistics table
- Mode
- Cumulative percentiles
- Median
- Relative positioning of mode median and mean
- Variance
- Standard deviation
- Inter-percentile range
- Normalized measures of spread - the CofV
- Graphical descriptionss of model results
- Showing probability ranges
- Overlaying histogram plots
- Scatter plots
- Effect of varying number of bars
- Sturges rule
- Relationship between cdf and density (histogram) plots
- Difficulty of interpreting the vertical scale
- Stochastic dominance tests
- Risk-return plots
- Second order cumulative probability plot
- Ascending and descending cumulative plots
- Tornado plot
- Box Plot
- Cumulative distribution function (cdf)
- Probability density function (pdf)
- Crude sensitivity analysis for identifying important input distributions
- Pareto Plot
- Trend plot
- Probability mass function (pmf)
- Overlaying cdf plots
- Cumulative Plot
- Simulation data table
- Statistics table
- Histogram Plot
- Spider plot
- Determining the width of histogram bars
- Plotting a variable with discrete and continuous elements
- Smoothing a histogram plot
- Risk analysis modeling techniques
- Monte Carlo simulation
- Monte Carlo simulation introduction
- Monte Carlo simulation in ModelRisk
- Filtering simulation results
- Output/Input Window
- Simulation Progress control
- Running multiple simulations
- Random number generation in ModelRisk
- Random sampling from input distributions
- How many Monte Carlo samples are enough?
- Probability distributions
- Distributions introduction
- Probability calculations in ModelRisk
- Selecting the appropriate distributions for your model
- List of distributions by category
- Distribution functions and the U parameter
- Univariate continuous distributions
- Beta distribution
- Beta Subjective distribution
- Four-parameter Beta distribution
- Bradford distribution
- Burr distribution
- Cauchy distribution
- Chi distribution
- Chi Squared distribution
- Continuous distributions introduction
- Continuous fitted distribution
- Cumulative ascending distribution
- Cumulative descending distribution
- Dagum distribution
- Erlang distribution
- Error distribution
- Error function distribution
- Exponential distribution
- Exponential family of distributions
- Extreme Value Minimum distribution
- Extreme Value Maximum distribution
- F distribution
- Fatigue Life distribution
- Gamma distribution
- Generalized Extreme Value distribution
- Generalized Logistic distribution
- Generalized Trapezoid Uniform (GTU) distribution
- Histogram distribution
- Hyperbolic-Secant distribution
- Inverse Gaussian distribution
- Johnson Bounded distribution
- Johnson Unbounded distribution
- Kernel Continuous Unbounded distribution
- Kumaraswamy distribution
- Kumaraswamy Four-parameter distribution
- Laplace distribution
- Levy distribution
- Lifetime Two-Parameter distribution
- Lifetime Three-Parameter distribution
- Lifetime Exponential distribution
- LogGamma distribution
- Logistic distribution
- LogLaplace distribution
- LogLogistic distribution
- LogLogistic Alternative parameter distribution
- LogNormal distribution
- LogNormal Alternative-parameter distribution
- LogNormal base B distribution
- LogNormal base E distribution
- LogTriangle distribution
- LogUniform distribution
- Noncentral Chi squared distribution
- Noncentral F distribution
- Normal distribution
- Normal distribution with alternative parameters
- Maxwell distribution
- Normal Mix distribution
- Relative distribution
- Ogive distribution
- Pareto (first kind) distribution
- Pareto (second kind) distribution
- Pearson Type 5 distribution
- Pearson Type 6 distribution
- Modified PERT distribution
- PERT distribution
- PERT Alternative-parameter distribution
- Reciprocal distribution
- Rayleigh distribution
- Skew Normal distribution
- Slash distribution
- SplitTriangle distribution
- Student-t distribution
- Three-parameter Student distribution
- Triangle distribution
- Triangle Alternative-parameter distribution
- Uniform distribution
- Weibull distribution
- Weibull Alternative-parameter distribution
- Three-Parameter Weibull distribution
- Univariate discrete distributions
- Discrete distributions introduction
- Bernoulli distribution
- Beta-Binomial distribution
- Beta-Geometric distribution
- Beta-Negative Binomial distribution
- Binomial distribution
- Burnt Finger Poisson distribution
- Delaporte distribution
- Discrete distribution
- Discrete Fitted distribution
- Discrete Uniform distribution
- Geometric distribution
- HypergeoM distribution
- Hypergeometric distribution
- HypergeoD distribution
- Inverse Hypergeometric distribution
- Logarithmic distribution
- Negative Binomial distribution
- Poisson distribution
- Poisson Uniform distribution
- Polya distribution
- Skellam distribution
- Step Uniform distribution
- Zero-modified counting distributions
- More on probability distributions
- Multivariate distributions
- Multivariate distributions introduction
- Dirichlet distribution
- Multinomial distribution
- Multivariate Hypergeometric distribution
- Multivariate Inverse Hypergeometric distribution type2
- Negative Multinomial distribution type 1
- Negative Multinomial distribution type 2
- Multivariate Inverse Hypergeometric distribution type1
- Multivariate Normal distribution
- More on probability distributions
- Approximating one distribution with another
- Approximations to the Inverse Hypergeometric Distribution
- Normal approximation to the Gamma Distribution
- Normal approximation to the Poisson Distribution
- Approximations to the Hypergeometric Distribution
- Stirlings formula for factorials
- Normal approximation to the Beta Distribution
- Approximation of one distribution with another
- Approximations to the Negative Binomial Distribution
- Normal approximation to the Student-t Distribution
- Approximations to the Binomial Distribution
- Normal_approximation_to_the_Binomial_distribution
- Poisson_approximation_to_the_Binomial_distribution
- Normal approximation to the Chi Squared Distribution
- Recursive formulas for discrete distributions
- Normal approximation to the Lognormal Distribution
- Normal approximations to other distributions
- Approximating one distribution with another
- Correlation modeling in risk analysis
- Common mistakes when adapting spreadsheet models for risk analysis
- More advanced risk analysis methods
- SIDs
- Modeling with objects
- ModelRisk database connectivity functions
- PK/PD modeling
- Value of information techniques
- Simulating with ordinary differential equations (ODEs)
- Optimization of stochastic models
- ModelRisk optimization extension introduction
- Optimization Settings
- Defining Simulation Requirements in an Optimization Model
- Defining Decision Constraints in an Optimization Model
- Optimization Progress control
- Defining Targets in an Optimization Model
- Defining Decision Variables in an Optimization Model
- Optimization Results
- Summing random variables
- Aggregate distributions introduction
- Aggregate modeling - Panjer's recursive method
- Adding correlation in aggregate calculations
- Sum of a random number of random variables
- Moments of an aggregate distribution
- Aggregate modeling in ModelRisk
- Aggregate modeling - Fast Fourier Transform (FFT) method
- How many random variables add up to a fixed total
- Aggregate modeling - compound Poisson approximation
- Aggregate modeling - De Pril's recursive method
- Testing and modeling causal relationships
- Stochastic time series
- Time series introduction
- Time series in ModelRisk
- Autoregressive models
- Thiel inequality coefficient
- Effect of an intervention at some uncertain point in time
- Log return of a Time Series
- Markov Chain models
- Seasonal time series
- Bounded random walk
- Time series modeling in finance
- Birth and death models
- Time series models with leading indicators
- Geometric Brownian Motion models
- Time series projection of events occurring randomly in time
- Simulation for six sigma
- ModelRisk's Six Sigma functions
- VoseSixSigmaCp
- VoseSixSigmaCpkLower
- VoseSixSigmaProbDefectShift
- VoseSixSigmaLowerBound
- VoseSixSigmaK
- VoseSixSigmaDefectShiftPPMUpper
- VoseSixSigmaDefectShiftPPMLower
- VoseSixSigmaDefectShiftPPM
- VoseSixSigmaCpm
- VoseSixSigmaSigmaLevel
- VoseSixSigmaCpkUpper
- VoseSixSigmaCpk
- VoseSixSigmaDefectPPM
- VoseSixSigmaProbDefectShiftLower
- VoseSixSigmaProbDefectShiftUpper
- VoseSixSigmaYield
- VoseSixSigmaUpperBound
- VoseSixSigmaZupper
- VoseSixSigmaZmin
- VoseSixSigmaZlower
- Modeling expert opinion
- Modeling expert opinion introduction
- Sources of error in subjective estimation
- Disaggregation
- Distributions used in modeling expert opinion
- A subjective estimate of a discrete quantity
- Incorporating differences in expert opinions
- Modeling opinion of a variable that covers several orders of magnitude
- Maximum entropy
- Probability theory and statistics
- Probability theory and statistics introduction
- Stochastic processes
- Stochastic processes introduction
- Poisson process
- Hypergeometric process
- The hypergeometric process
- Number in a sample with a particular characteristic in a hypergeometric process
- Number of hypergeometric samples to get a specific number of successes
- Number of samples taken to have an observed s in a hypergeometric process
- Estimate of population and sub-population sizes in a hypergeometric process
- The binomial process
- Renewal processes
- Mixture processes
- Martingales
- Estimating model parameters from data
- The basics
- Probability equations
- Probability theorems and useful concepts
- Probability parameters
- Probability rules and diagrams
- The definition of probability
- The basics of probability theory introduction
- Fitting probability models to data
- Fitting time series models to data
- Fitting correlation structures to data
- Fitting in ModelRisk
- Fitting probability distributions to data
- Fitting distributions to data
- Method of Moments (MoM)
- Check the quality of your data
- Kolmogorov-Smirnoff (K-S) Statistic
- Anderson-Darling (A-D) Statistic
- Goodness of fit statistics
- The Chi-Squared Goodness-of-Fit Statistic
- Determining the joint uncertainty distribution for parameters of a distribution
- Using Method of Moments with the Bootstrap
- Maximum Likelihood Estimates (MLEs)
- Fitting a distribution to truncated censored or binned data
- Critical Values and Confidence Intervals for Goodness-of-Fit Statistics
- Matching the properties of the variable and distribution
- Transforming discrete data before performing a parametric distribution fit
- Does a parametric distribution exist that is well known to fit this type of variable?
- Censored data
- Fitting a continuous non-parametric second-order distribution to data
- Goodness of Fit Plots
- Fitting a second order Normal distribution to data
- Using Goodness-of Fit Statistics to optimize Distribution Fitting
- Information criteria - SIC HQIC and AIC
- Fitting a second order parametric distribution to observed data
- Fitting a distribution for a continuous variable
- Does the random variable follow a stochastic process with a well-known model?
- Fitting a distribution for a discrete variable
- Fitting a discrete non-parametric second-order distribution to data
- Fitting a continuous non-parametric first-order distribution to data
- Fitting a first order parametric distribution to observed data
- Fitting a discrete non-parametric first-order distribution to data
- Fitting distributions to data
- Technical subjects
- Comparison of Classical and Bayesian methods
- Comparison of classic and Bayesian estimate of Normal distribution parameters
- Comparison of classic and Bayesian estimate of intensity lambda in a Poisson process
- Comparison of classic and Bayesian estimate of probability p in a binomial process
- Which technique should you use?
- Comparison of classic and Bayesian estimate of mean "time" beta in a Poisson process
- Classical statistics
- Bayesian
- Bootstrap
- The Bootstrap
- Linear regression parametric Bootstrap
- The Jackknife
- Multiple variables Bootstrap Example 2: Difference between two population means
- Linear regression non-parametric Bootstrap
- The parametric Bootstrap
- Bootstrap estimate of prevalence
- Estimating parameters for multiple variables
- Example: Parametric Bootstrap estimate of the mean of a Normal distribution with known standard deviation
- The non-parametric Bootstrap
- Example: Parametric Bootstrap estimate of mean number of calls per hour at a telephone exchange
- The Bootstrap likelihood function for Bayesian inference
- Multiple variables Bootstrap Example 1: Estimate of regression parameters
- Bayesian inference
- Uninformed priors
- Conjugate priors
- Prior distributions
- Bayesian analysis with threshold data
- Bayesian analysis example: gender of a random sample of people
- Informed prior
- Simulating a Bayesian inference calculation
- Hyperparameters
- Hyperparameter example: Micro-fractures on turbine blades
- Constructing a Bayesian inference posterior distribution in Excel
- Bayesian analysis example: Tigers in the jungle
- Markov chain Monte Carlo (MCMC) simulation
- Introduction to Bayesian inference concepts
- Bayesian estimate of the mean of a Normal distribution with known standard deviation
- Bayesian estimate of the mean of a Normal distribution with unknown standard deviation
- Determining prior distributions for correlated parameters
- Improper priors
- The Jacobian transformation
- Subjective prior based on data
- Taylor series approximation to a Bayesian posterior distribution
- Bayesian analysis example: The Monty Hall problem
- Determining prior distributions for uncorrelated parameters
- Subjective priors
- Normal approximation to the Beta posterior distribution
- Bayesian analysis example: identifying a weighted coin
- Bayesian estimate of the standard deviation of a Normal distribution with known mean
- Likelihood functions
- Bayesian estimate of the standard deviation of a Normal distribution with unknown mean
- Determining a prior distribution for a single parameter estimate
- Simulating from a constructed posterior distribution
- Bootstrap
- Comparison of Classical and Bayesian methods
- Analyzing and using data introduction
- Data Object
- Vose probability calculation
- Bayesian model averaging
- Miscellaneous
- Excel and ModelRisk model design and validation techniques
- Using range names for model clarity
- Color coding models for clarity
- Compare with known answers
- Checking units propagate correctly
- Stressing parameter values
- Model Validation and behavior introduction
- Informal auditing
- Analyzing outputs
- View random scenarios on screen and check for credibility
- Split up complex formulas (megaformulas)
- Building models that are efficient
- Comparing predictions against reality
- Numerical integration
- Comparing results of alternative models
- Building models that are easy to check and modify
- Model errors
- Model design introduction
- About array functions in Excel
- Excel and ModelRisk model design and validation techniques
- Monte Carlo simulation
- RISK ANALYSIS SOFTWARE
- Risk analysis software from Vose Software
- ModelRisk - risk modeling in Excel
- ModelRisk functions explained
- VoseCopulaOptimalFit and related functions
- VoseTimeOptimalFit and related functions
- VoseOptimalFit and related functions
- VoseXBounds
- VoseCLTSum
- VoseAggregateMoments
- VoseRawMoments
- VoseSkewness
- VoseMoments
- VoseKurtosis
- VoseAggregatePanjer
- VoseAggregateFFT
- VoseCombined
- VoseCopulaBiGumbel
- VoseCopulaBiClayton
- VoseCopulaBiNormal
- VoseCopulaBiT
- VoseKendallsTau
- VoseRiskEvent
- VoseCopulaBiFrank
- VoseCorrMatrix
- VoseRank
- VoseValidCorrmat
- VoseSpearman
- VoseCopulaData
- VoseCorrMatrixU
- VoseTimeSeasonalGBM
- VoseMarkovSample
- VoseMarkovMatrix
- VoseThielU
- VoseTimeEGARCH
- VoseTimeAPARCH
- VoseTimeARMA
- VoseTimeDeath
- VoseTimeAR1
- VoseTimeAR2
- VoseTimeARCH
- VoseTimeMA2
- VoseTimeGARCH
- VoseTimeGBMJDMR
- VoseTimePriceInflation
- VoseTimeGBMMR
- VoseTimeWageInflation
- VoseTimeLongTermInterestRate
- VoseTimeMA1
- VoseTimeGBM
- VoseTimeGBMJD
- VoseTimeShareYields
- VoseTimeYule
- VoseTimeShortTermInterestRate
- VoseDominance
- VoseLargest
- VoseSmallest
- VoseShift
- VoseStopSum
- VoseEigenValues
- VosePrincipleEsscher
- VoseAggregateMultiFFT
- VosePrincipleEV
- VoseCopulaMultiNormal
- VoseRunoff
- VosePrincipleRA
- VoseSumProduct
- VosePrincipleStdev
- VosePoissonLambda
- VoseBinomialP
- VosePBounds
- VoseAIC
- VoseHQIC
- VoseSIC
- VoseOgive1
- VoseFrequency
- VoseOgive2
- VoseNBootStdev
- VoseNBoot
- VoseSimulate
- VoseNBootPaired
- VoseAggregateMC
- VoseMean
- VoseStDev
- VoseAggregateMultiMoments
- VoseDeduct
- VoseExpression
- VoseLargestSet
- VoseKthSmallest
- VoseSmallestSet
- VoseKthLargest
- VoseNBootCofV
- VoseNBootPercentile
- VoseExtremeRange
- VoseNBootKurt
- VoseCopulaMultiClayton
- VoseNBootMean
- VoseTangentPortfolio
- VoseNBootVariance
- VoseNBootSkewness
- VoseIntegrate
- VoseInterpolate
- VoseCopulaMultiGumbel
- VoseCopulaMultiT
- VoseAggregateMultiMC
- VoseCopulaMultiFrank
- VoseTimeMultiMA1
- VoseTimeMultiMA2
- VoseTimeMultiGBM
- VoseTimeMultBEKK
- VoseAggregateDePril
- VoseTimeMultiAR1
- VoseTimeWilkie
- VoseTimeDividends
- VoseTimeMultiAR2
- VoseRuinFlag
- VoseRuinTime
- VoseDepletionShortfall
- VoseDepletion
- VoseDepletionFlag
- VoseDepletionTime
- VosejProduct
- VoseCholesky
- VoseTimeSimulate
- VoseNBootSeries
- VosejkProduct
- VoseRuinSeverity
- VoseRuin
- VosejkSum
- VoseTimeDividendsA
- VoseRuinNPV
- VoseTruncData
- VoseSample
- VoseIdentity
- VoseCopulaSimulate
- VoseSortA
- VoseFrequencyCumulA
- VoseAggregateDeduct
- VoseMeanExcessP
- VoseProb10
- VoseSpearmanU
- VoseSortD
- VoseFrequencyCumulD
- VoseRuinMaxSeverity
- VoseMeanExcessX
- VoseRawMoment3
- VosejSum
- VoseRawMoment4
- VoseNBootMoments
- VoseVariance
- VoseTimeShortTermInterestRateA
- VoseTimeLongTermInterestRateA
- VoseProb
- VoseDescription
- VoseCofV
- VoseAggregateProduct
- VoseEigenVectors
- VoseTimeWageInflationA
- VoseRawMoment1
- VosejSumInf
- VoseRawMoment2
- VoseShuffle
- VoseRollingStats
- VoseSplice
- VoseTSEmpiricalFit
- VoseTimeShareYieldsA
- VoseParameters
- VoseAggregateTranche
- VoseCovToCorr
- VoseCorrToCov
- VoseLLH
- VoseTimeSMEThreePoint
- VoseDataObject
- VoseCopulaDataSeries
- VoseDataRow
- VoseDataMin
- VoseDataMax
- VoseTimeSME2Perc
- VoseTimeSMEUniform
- VoseTimeSMESaturation
- VoseOutput
- VoseInput
- VoseTimeSMEPoisson
- VoseTimeBMAObject
- VoseBMAObject
- VoseBMAProb10
- VoseBMAProb
- VoseCopulaBMA
- VoseCopulaBMAObject
- VoseTimeEmpiricalFit
- VoseTimeBMA
- VoseBMA
- VoseSimKurtosis
- VoseOptConstraintMin
- VoseSimProbability
- VoseCurrentSample
- VoseCurrentSim
- VoseLibAssumption
- VoseLibReference
- VoseSimMoments
- VoseOptConstraintMax
- VoseSimMean
- VoseOptDecisionContinuous
- VoseOptRequirementEquals
- VoseOptRequirementMax
- VoseOptRequirementMin
- VoseOptTargetMinimize
- VoseOptConstraintEquals
- VoseSimVariance
- VoseSimSkewness
- VoseSimTable
- VoseSimCofV
- VoseSimPercentile
- VoseSimStDev
- VoseOptTargetValue
- VoseOptTargetMaximize
- VoseOptDecisionDiscrete
- VoseSimMSE
- VoseMin
- VoseMin
- VoseOptDecisionList
- VoseOptDecisionBoolean
- VoseOptRequirementBetween
- VoseOptConstraintBetween
- VoseSimMax
- VoseSimSemiVariance
- VoseSimSemiStdev
- VoseSimMeanDeviation
- VoseSimMin
- VoseSimCVARp
- VoseSimCVARx
- VoseSimCorrelation
- VoseSimCorrelationMatrix
- VoseOptConstraintString
- VoseOptCVARx
- VoseOptCVARp
- VoseOptPercentile
- VoseSimValue
- VoseSimStop
- Precision Control Functions
- VoseAggregateDiscrete
- VoseTimeMultiGARCH
- VoseTimeGBMVR
- VoseTimeGBMAJ
- VoseTimeGBMAJVR
- VoseSID
- Generalized Pareto Distribution (GPD)
- Generalized Pareto Distribution (GPD) Equations
- Three-Point Estimate Distribution
- Three-Point Estimate Distribution Equations
- VoseCalibrate
- ModelRisk interfaces
- Integrate
- Data Viewer
- Stochastic Dominance
- Library
- Correlation Matrix
- Portfolio Optimization Model
- Common elements of ModelRisk interfaces
- Risk Event
- Extreme Values
- Select Distribution
- Combined Distribution
- Aggregate Panjer
- Interpolate
- View Function
- Find Function
- Deduct
- Ogive
- AtRISK model converter
- Aggregate Multi FFT
- Stop Sum
- Crystal Ball model converter
- Aggregate Monte Carlo
- Splicing Distributions
- Subject Matter Expert (SME) Time Series Forecasts
- Aggregate Multivariate Monte Carlo
- Ordinary Differential Equation tool
- Aggregate FFT
- More on Conversion
- Multivariate Copula
- Bivariate Copula
- Univariate Time Series
- Modeling expert opinion in ModelRisk
- Multivariate Time Series
- Sum Product
- Aggregate DePril
- Aggregate Discrete
- Expert
- ModelRisk introduction
- Building and running a simple example model
- Distributions in ModelRisk
- List of all ModelRisk functions
- Custom applications and macros
- ModelRisk functions explained
- Tamara - project risk analysis
- Introduction to Tamara project risk analysis software
- Launching Tamara
- Importing a schedule
- Assigning uncertainty to the amount of work in the project
- Assigning uncertainty to productivity levels in the project
- Adding risk events to the project schedule
- Adding cost uncertainty to the project schedule
- Saving the Tamara model
- Running a Monte Carlo simulation in Tamara
- Reviewing the simulation results in Tamara
- Using Tamara results for cost and financial risk analysis
- Creating, updating and distributing a Tamara report
- Tips for creating a schedule model suitable for Monte Carlo simulation
- Random number generator and sampling algorithms used in Tamara
- Probability distributions used in Tamara
- Correlation with project schedule risk analysis
- Pelican - enterprise risk management