Fitting in ModelRisk
See also: Fitting distributions to data,Estimating model parameters from data, Goodness of fit statistics, Comparing fitted models using the SIC HQIC or AIC information criterion

ModelRisk allows one to fit a distribution, time series or a copula to spreadsheet data.
Windows for fitting
- Distribution Fit
- Bivariate Copula Fit
- Multivariate Copula Fit
- Empirical Copula
- Time Series Fit
All fits are performed using Maximum Likelihood Estimation (MLE) methods. In the fitting windows (see list on the right) different fitted models can be ranked according to SIC, HQIC or AIC (Akaike) information criteria.
About the uncertainty parameter
The uncertainty parameter is common to all ModelRisk fitting functions. It allows the inclusion of uncertainty about the fitted model parameter estimates. Unfortunately, it is common practice in risk analysis to use just the maximum likelihood estimates (MLEs) for a fitted distribution, copula or time series. However, when there are relatively few data available or when the model needs to be precise, omitting the uncertainty about the true parameter values can lead to significant underestimation of the model output uncertainty.
The Uncertainty parameter is set to FALSE by default (i.e. returns MLEs or projections based on MLEs) to coincide with common practice, but we strongly recommend setting it to TRUE. Uncertainty values are then generated for the fitted parameters using parametric bootstrapping techniques, which has the great advantage of allowing correlation structure between uncertain parameters and non-normal marginal uncertainty distributions, the latter being an important constraint of more classical methods based on asymptotic results (i.e. when the amount of data approaches infinity).
Distribution fitting functions
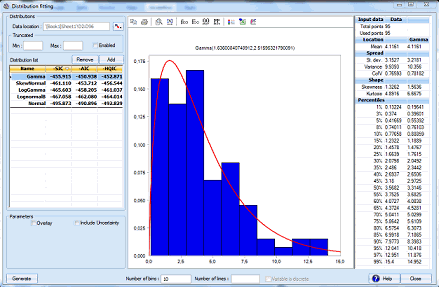
For non-parametric bootstrapping techniques for estimation of parameters, ModelRisk has the VoseNBoot functions.
For each univariate distribution in ModelRisk, a number of fitting functions are included:
VoseDistributionFit
Returns a sampled value from a distribution fitted to the data using Maximum Likelihood Estimation. The general syntax is:
=VoseDistributionFit({data}, Uncertainty, U)
where Distribution is replaced by the name of the distribution.
The parameters are:
-
{data} - array containing data to fit the distribution to.
-
Uncertainty - optional boolean parameter. Set TRUE to include uncertainty about the fitted distribution (as explained above), and FALSE (default) to use the MLE. When set to TRUE, a new fitted parameter value is used on each spreadsheet recalculation through bootstrapping techniques.
-
U - optional parameter specifying the cumulative percentile of the distribution. If omitted the function generates random values. Also see Distribution functions and the U parameter.
For example, if DataSet is an array of data, VoseNormalFit(DataSet) will return a random value from a Normal distribution that is the MLE fit to the DataSet. VoseNormalFit(DataSet,1) will use bootstrapping to simulate the uncertainty about the fitted parameters.
If we want to use VoseDistributionFit to generate multiple random values from a fitted distribution with uncertainty included (i.e. Uncertainty=TRUE), there are two ways to do this:
1. In one cell, or in many cells, but not as array function
2. In many cells as array function
In the first case, the uncertainty and variability are mixed, because each random value is sampled form a different distribution. However in the second case, all random values are sampled from the same distribution and the distribution will change only with the next iteration.
You can read more about separating uncertainty and randomness in the Separating uncertainty from randomness and variability introduction topic.
VoseDistributionFitP
Array function that returns the parameters of the VoseDistribution fitted to the data. The general syntax is:
{=VoseDistributionFitP({data}, Uncertainty)}
where Distribution is replaced by the name of the distribution.
-
{data} - array containing data to fit the distribution to.
-
Uncertainty - optional boolean parameter. Set TRUE to include uncertainty about the fitted distribution (as explained above), and FALSE (default) to use the MLE.
The output array size should be one-dimensional, with the number of cells equal to the number of estimated parameters. The fitted parameters are returned in the same order as they are in the corresponding VoseDistribution (simulation) function.
So, for example,
{=VoseNormalFitP({1,2,2,3},0)}
should have an output of two cells. The function will return best fitting values for Mu and Sigma, in that order, because the ModelRisk syntax for the normal distribution is VoseNormal(Mu, Sigma).
VoseDistributionFitObject
Constructs a distribution object of the fitted distribution. General syntax:
=VoseDistributionFitObject({data}, Uncertainty)
where Distribution is replaced by the name of the distribution.
-
{data} - array containing data to fit the distribution to.
-
Uncertainty - optional boolean parameter. Set TRUE to include uncertainty about the fitted distribution, and FALSE (default) to use the MLE.
Time series fitting functions

For each time series in ModelRisk the following fitting functions are included.
VoseTimeSeriesFit
Generates a sequence of random values of a time series model fitted to the data using Maximum Likelihood Estimation. Syntax:
{=VoseTimeSeriesFit({data}, Uncertainty, Log Returns, Initial Value)}
where Series is replaced by the name of the time series.
-
{data} - array containing data to fit the time series to.
-
Uncertainty - optional boolean parameter. Set TRUE to include uncertainty about the fitted time series (as explained above), and FALSE (default) to use the MLE.
-
Log Returns - optional boolean (TRUE/FALSE) parameter that specifies whether the time series are in log returns. Default is FALSE.
-
Initial Value - last known historic value. The generated time series values will continue on from this value. Should only be provided if the Log Return parameter is set to FALSE or omitted.
For example, if DataSet is an array of historical data, {=VoseTimeAR1Fit(DataSet)}) will return a random value from a AR1 time series that is the MLE fit to the DataSet.
{=VoseTimeAR1Fit(DataSet,1)} will use bootstrapping to simulate the uncertainty about the fitted parameters.
When the data fitted to a time series takes negative values ModelRisk recognizes that these data can only be log returns, not the actual value of the variable. In this situation, the Log Return option is automatically selected and ModelRisk will produce a forecast of log returns, making Initial Value redundant as described above.
VoseTimeSeriesFitP
Array function that returns the parameters of a time series model fitted to the data using Maximum Likelihood Estimation. General syntax:
=VoseTimeSeriesFit({data}, Uncertainty, Log Returns)
where Series is replaced by the name of the time series.
-
-
{data} - array containing data to fit the time series to.
-
Uncertainty - optional boolean parameter. Set TRUE to include uncertainty about the fitted time series, and FALSE (default) to use the MLE.
-
Log Returns - optional boolean (TRUE/FALSE) parameter that specifies whether the time series are in log returns. Default is FALSE.
-
For example, if DataSet is an array of historical data, {=VoseTimeAR1FitP(DataSet)}) will return the parameters from a AR1 time series that is the MLE fit to the DataSet.
The output array size should be one-dimensional, with the number of cells equal to the number of estimated parameters. The fitted parameters are returned in the same order as they are in the corresponding VoseTimeSeries (simulating) function.
So, for example,
{=VoseTimeGBMFitP({1,2,2,3},0)}
should have an output of two cells. The function will return best fitting values for Mu and Sigma, in that order, because the ModelRisk syntax for modeling an GBM Time Series is VoseTimeGBM(Mu, Sigma,[other parameters]).
Copula fitting functions
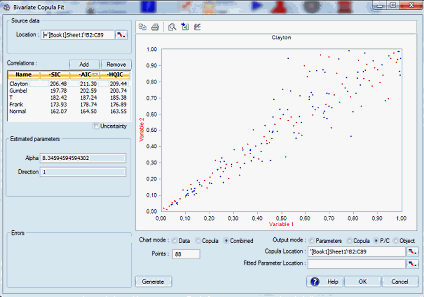 For each of the Copulas available in ModelRisk, the following fitting functions are included:
For each of the Copulas available in ModelRisk, the following fitting functions are included:
VoseCopulaFit
Array function that generates values from the bivariate or multivariate copula fitted to the data using Maximum Likelihood Estimation. The syntax for fitting bivariate respectively multivariate copula is
{=VoseCopulaBiNameFit({data},Data_in_rows,Uncertainty)}
{=VoseCopulaMultiNameFit({data},Data_in_rows,Uncertainty)}
where Name is replaced by the name of the copula.
For the bivariate archimedean copulas (Clayton, Gumbel, Frank) this function chooses the direction of correlation that best fits the data and simulates from the fitted copula. Alternatively one can use the standard multivariate copula fitting functions, even for bivariate data, which will assume the standard direction of the fitted copula.
-
{data} - the array of data to fit the copula to. This should be an 2-dimensional array for fitting a bivariate copula, or n-dimensional where n>2 for fitting a multivariate copula.
-
Data_in_rows - optional boolean parameter that specifies whether the data is in columns (FALSE,default) or rows (TRUE).
-
Uncertainty - optional boolean parameter. Set TRUE to include uncertainty about the fitted time series, and FALSE (default) to use the MLE.
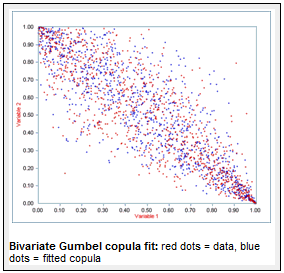 The scatter plot shown on the right illustrates a Gumbel copula fitted to bivariate data.
The scatter plot shown on the right illustrates a Gumbel copula fitted to bivariate data.
Note from the scatter plot that the data are negatively correlated. The bivariate Gumbel can adapt to this by rotating the fitted copula, and gives a fitted Direction parameter of 3, and a value of theta = 3.036.
In contrast, the multivariate Gumbel copula only has Direction = 1 at its disposal so would provide a very poor fit.
VoseCopulaFitP
Array function that returns the parameter(s) from the bivariate or multivariate copula fitted to the data. The syntax is:
{=VoseCopulaBiNameFitP({data},Data_in_rows,Uncertainty)}
{=VoseCopulaMultiNameFitP({data},Data_in_rows,Uncertainty)}
where Name is replaced by the name of the copula.
-
{data} - the array of data to fit the copula to. This should be an 2-dimensional array for fitting a bivariate copula, or n-dimensional where n>2 for fitting a multivariate copula.
-
Data_in_rows - optional boolean parameter that specifies whether the data is in columns (FALSE,default) or rows (TRUE).
-
Uncertainty - optional boolean parameter. Set TRUE to include uncertainty about the fitted time series, and FALSE (default) to use the MLE.
The output array size should be one-dimensional, with the number of cells equal to the number of estimated parameters. The fitted parameters are returned in the same order as they are in the corresponding VoseCopula (simulating) function.
So, for example,
{=VoseCopulaBiTFitP(Data,0)}
should have an output of two cells. The function will return best fitting values for the Nu and Covariance parameters, in that order, because the ModelRisk syntax for modeling a bivariate T copula is VoseCopulaBiT(Nu,Covariance).
VoseCopulaData
This array function generates random values from an empirical copula constructed entirely from the correlation pattern of given data. Syntax:
{=VoseCopuladata({data},Data_in_rows)}
-
{data} - the spreadsheet data from which to construct the copula. This should be at least a two-dimensional array.
-
Data_in_rows - a boolean parameter (TRUE/FALSE) that specifies whether the data is oriented in rows (TRUE) or not (FALSE, default)
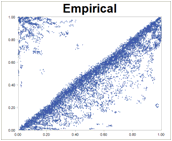 Note the difference between constructing an empirical copula, and fitting an existing type of copula:
Note the difference between constructing an empirical copula, and fitting an existing type of copula:
When fitting a copula, we determine the parameter of the copula that makes for a best fit to the data, but retaining the copula's functional form. With the empirical copula, the functional form itself (not just the parameter) is based on the data, making it a flexible tool for capturing any correlation pattern, however unusual (for example the one shown on the right).
An illustration of the use of the empirical copula on the right is given in the example model
 VoseCopulaData.xls
VoseCopulaData.xls
Navigation
- Risk management
- Risk management introduction
- What are risks and opportunities?
- Planning a risk analysis
- Clearly stating risk management questions
- Evaluating risk management options
- Introduction to risk analysis
- The quality of a risk analysis
- Using risk analysis to make better decisions
- Explaining a models assumptions
- Statistical descriptions of model outputs
- Simulation Statistical Results
- Preparing a risk analysis report
- Graphical descriptions of model outputs
- Presenting and using results introduction
- Statistical descriptions of model results
- Mean deviation (MD)
- Range
- Semi-variance and semi-standard deviation
- Kurtosis (K)
- Mean
- Skewness (S)
- Conditional mean
- Custom simulation statistics table
- Mode
- Cumulative percentiles
- Median
- Relative positioning of mode median and mean
- Variance
- Standard deviation
- Inter-percentile range
- Normalized measures of spread - the CofV
- Graphical descriptionss of model results
- Showing probability ranges
- Overlaying histogram plots
- Scatter plots
- Effect of varying number of bars
- Sturges rule
- Relationship between cdf and density (histogram) plots
- Difficulty of interpreting the vertical scale
- Stochastic dominance tests
- Risk-return plots
- Second order cumulative probability plot
- Ascending and descending cumulative plots
- Tornado plot
- Box Plot
- Cumulative distribution function (cdf)
- Probability density function (pdf)
- Crude sensitivity analysis for identifying important input distributions
- Pareto Plot
- Trend plot
- Probability mass function (pmf)
- Overlaying cdf plots
- Cumulative Plot
- Simulation data table
- Statistics table
- Histogram Plot
- Spider plot
- Determining the width of histogram bars
- Plotting a variable with discrete and continuous elements
- Smoothing a histogram plot
- Risk analysis modeling techniques
- Monte Carlo simulation
- Monte Carlo simulation introduction
- Monte Carlo simulation in ModelRisk
- Filtering simulation results
- Output/Input Window
- Simulation Progress control
- Running multiple simulations
- Random number generation in ModelRisk
- Random sampling from input distributions
- How many Monte Carlo samples are enough?
- Probability distributions
- Distributions introduction
- Probability calculations in ModelRisk
- Selecting the appropriate distributions for your model
- List of distributions by category
- Distribution functions and the U parameter
- Univariate continuous distributions
- Beta distribution
- Beta Subjective distribution
- Four-parameter Beta distribution
- Bradford distribution
- Burr distribution
- Cauchy distribution
- Chi distribution
- Chi Squared distribution
- Continuous distributions introduction
- Continuous fitted distribution
- Cumulative ascending distribution
- Cumulative descending distribution
- Dagum distribution
- Erlang distribution
- Error distribution
- Error function distribution
- Exponential distribution
- Exponential family of distributions
- Extreme Value Minimum distribution
- Extreme Value Maximum distribution
- F distribution
- Fatigue Life distribution
- Gamma distribution
- Generalized Extreme Value distribution
- Generalized Logistic distribution
- Generalized Trapezoid Uniform (GTU) distribution
- Histogram distribution
- Hyperbolic-Secant distribution
- Inverse Gaussian distribution
- Johnson Bounded distribution
- Johnson Unbounded distribution
- Kernel Continuous Unbounded distribution
- Kumaraswamy distribution
- Kumaraswamy Four-parameter distribution
- Laplace distribution
- Levy distribution
- Lifetime Two-Parameter distribution
- Lifetime Three-Parameter distribution
- Lifetime Exponential distribution
- LogGamma distribution
- Logistic distribution
- LogLaplace distribution
- LogLogistic distribution
- LogLogistic Alternative parameter distribution
- LogNormal distribution
- LogNormal Alternative-parameter distribution
- LogNormal base B distribution
- LogNormal base E distribution
- LogTriangle distribution
- LogUniform distribution
- Noncentral Chi squared distribution
- Noncentral F distribution
- Normal distribution
- Normal distribution with alternative parameters
- Maxwell distribution
- Normal Mix distribution
- Relative distribution
- Ogive distribution
- Pareto (first kind) distribution
- Pareto (second kind) distribution
- Pearson Type 5 distribution
- Pearson Type 6 distribution
- Modified PERT distribution
- PERT distribution
- PERT Alternative-parameter distribution
- Reciprocal distribution
- Rayleigh distribution
- Skew Normal distribution
- Slash distribution
- SplitTriangle distribution
- Student-t distribution
- Three-parameter Student distribution
- Triangle distribution
- Triangle Alternative-parameter distribution
- Uniform distribution
- Weibull distribution
- Weibull Alternative-parameter distribution
- Three-Parameter Weibull distribution
- Univariate discrete distributions
- Discrete distributions introduction
- Bernoulli distribution
- Beta-Binomial distribution
- Beta-Geometric distribution
- Beta-Negative Binomial distribution
- Binomial distribution
- Burnt Finger Poisson distribution
- Delaporte distribution
- Discrete distribution
- Discrete Fitted distribution
- Discrete Uniform distribution
- Geometric distribution
- HypergeoM distribution
- Hypergeometric distribution
- HypergeoD distribution
- Inverse Hypergeometric distribution
- Logarithmic distribution
- Negative Binomial distribution
- Poisson distribution
- Poisson Uniform distribution
- Polya distribution
- Skellam distribution
- Step Uniform distribution
- Zero-modified counting distributions
- More on probability distributions
- Multivariate distributions
- Multivariate distributions introduction
- Dirichlet distribution
- Multinomial distribution
- Multivariate Hypergeometric distribution
- Multivariate Inverse Hypergeometric distribution type2
- Negative Multinomial distribution type 1
- Negative Multinomial distribution type 2
- Multivariate Inverse Hypergeometric distribution type1
- Multivariate Normal distribution
- More on probability distributions
- Approximating one distribution with another
- Approximations to the Inverse Hypergeometric Distribution
- Normal approximation to the Gamma Distribution
- Normal approximation to the Poisson Distribution
- Approximations to the Hypergeometric Distribution
- Stirlings formula for factorials
- Normal approximation to the Beta Distribution
- Approximation of one distribution with another
- Approximations to the Negative Binomial Distribution
- Normal approximation to the Student-t Distribution
- Approximations to the Binomial Distribution
- Normal_approximation_to_the_Binomial_distribution
- Poisson_approximation_to_the_Binomial_distribution
- Normal approximation to the Chi Squared Distribution
- Recursive formulas for discrete distributions
- Normal approximation to the Lognormal Distribution
- Normal approximations to other distributions
- Approximating one distribution with another
- Correlation modeling in risk analysis
- Common mistakes when adapting spreadsheet models for risk analysis
- More advanced risk analysis methods
- SIDs
- Modeling with objects
- ModelRisk database connectivity functions
- PK/PD modeling
- Value of information techniques
- Simulating with ordinary differential equations (ODEs)
- Optimization of stochastic models
- ModelRisk optimization extension introduction
- Optimization Settings
- Defining Simulation Requirements in an Optimization Model
- Defining Decision Constraints in an Optimization Model
- Optimization Progress control
- Defining Targets in an Optimization Model
- Defining Decision Variables in an Optimization Model
- Optimization Results
- Summing random variables
- Aggregate distributions introduction
- Aggregate modeling - Panjer's recursive method
- Adding correlation in aggregate calculations
- Sum of a random number of random variables
- Moments of an aggregate distribution
- Aggregate modeling in ModelRisk
- Aggregate modeling - Fast Fourier Transform (FFT) method
- How many random variables add up to a fixed total
- Aggregate modeling - compound Poisson approximation
- Aggregate modeling - De Pril's recursive method
- Testing and modeling causal relationships
- Stochastic time series
- Time series introduction
- Time series in ModelRisk
- Autoregressive models
- Thiel inequality coefficient
- Effect of an intervention at some uncertain point in time
- Log return of a Time Series
- Markov Chain models
- Seasonal time series
- Bounded random walk
- Time series modeling in finance
- Birth and death models
- Time series models with leading indicators
- Geometric Brownian Motion models
- Time series projection of events occurring randomly in time
- Simulation for six sigma
- ModelRisk's Six Sigma functions
- VoseSixSigmaCp
- VoseSixSigmaCpkLower
- VoseSixSigmaProbDefectShift
- VoseSixSigmaLowerBound
- VoseSixSigmaK
- VoseSixSigmaDefectShiftPPMUpper
- VoseSixSigmaDefectShiftPPMLower
- VoseSixSigmaDefectShiftPPM
- VoseSixSigmaCpm
- VoseSixSigmaSigmaLevel
- VoseSixSigmaCpkUpper
- VoseSixSigmaCpk
- VoseSixSigmaDefectPPM
- VoseSixSigmaProbDefectShiftLower
- VoseSixSigmaProbDefectShiftUpper
- VoseSixSigmaYield
- VoseSixSigmaUpperBound
- VoseSixSigmaZupper
- VoseSixSigmaZmin
- VoseSixSigmaZlower
- Modeling expert opinion
- Modeling expert opinion introduction
- Sources of error in subjective estimation
- Disaggregation
- Distributions used in modeling expert opinion
- A subjective estimate of a discrete quantity
- Incorporating differences in expert opinions
- Modeling opinion of a variable that covers several orders of magnitude
- Maximum entropy
- Probability theory and statistics
- Probability theory and statistics introduction
- Stochastic processes
- Stochastic processes introduction
- Poisson process
- Hypergeometric process
- The hypergeometric process
- Number in a sample with a particular characteristic in a hypergeometric process
- Number of hypergeometric samples to get a specific number of successes
- Number of samples taken to have an observed s in a hypergeometric process
- Estimate of population and sub-population sizes in a hypergeometric process
- The binomial process
- Renewal processes
- Mixture processes
- Martingales
- Estimating model parameters from data
- The basics
- Probability equations
- Probability theorems and useful concepts
- Probability parameters
- Probability rules and diagrams
- The definition of probability
- The basics of probability theory introduction
- Fitting probability models to data
- Fitting time series models to data
- Fitting correlation structures to data
- Fitting in ModelRisk
- Fitting probability distributions to data
- Fitting distributions to data
- Method of Moments (MoM)
- Check the quality of your data
- Kolmogorov-Smirnoff (K-S) Statistic
- Anderson-Darling (A-D) Statistic
- Goodness of fit statistics
- The Chi-Squared Goodness-of-Fit Statistic
- Determining the joint uncertainty distribution for parameters of a distribution
- Using Method of Moments with the Bootstrap
- Maximum Likelihood Estimates (MLEs)
- Fitting a distribution to truncated censored or binned data
- Critical Values and Confidence Intervals for Goodness-of-Fit Statistics
- Matching the properties of the variable and distribution
- Transforming discrete data before performing a parametric distribution fit
- Does a parametric distribution exist that is well known to fit this type of variable?
- Censored data
- Fitting a continuous non-parametric second-order distribution to data
- Goodness of Fit Plots
- Fitting a second order Normal distribution to data
- Using Goodness-of Fit Statistics to optimize Distribution Fitting
- Information criteria - SIC HQIC and AIC
- Fitting a second order parametric distribution to observed data
- Fitting a distribution for a continuous variable
- Does the random variable follow a stochastic process with a well-known model?
- Fitting a distribution for a discrete variable
- Fitting a discrete non-parametric second-order distribution to data
- Fitting a continuous non-parametric first-order distribution to data
- Fitting a first order parametric distribution to observed data
- Fitting a discrete non-parametric first-order distribution to data
- Fitting distributions to data
- Technical subjects
- Comparison of Classical and Bayesian methods
- Comparison of classic and Bayesian estimate of Normal distribution parameters
- Comparison of classic and Bayesian estimate of intensity lambda in a Poisson process
- Comparison of classic and Bayesian estimate of probability p in a binomial process
- Which technique should you use?
- Comparison of classic and Bayesian estimate of mean "time" beta in a Poisson process
- Classical statistics
- Bayesian
- Bootstrap
- The Bootstrap
- Linear regression parametric Bootstrap
- The Jackknife
- Multiple variables Bootstrap Example 2: Difference between two population means
- Linear regression non-parametric Bootstrap
- The parametric Bootstrap
- Bootstrap estimate of prevalence
- Estimating parameters for multiple variables
- Example: Parametric Bootstrap estimate of the mean of a Normal distribution with known standard deviation
- The non-parametric Bootstrap
- Example: Parametric Bootstrap estimate of mean number of calls per hour at a telephone exchange
- The Bootstrap likelihood function for Bayesian inference
- Multiple variables Bootstrap Example 1: Estimate of regression parameters
- Bayesian inference
- Uninformed priors
- Conjugate priors
- Prior distributions
- Bayesian analysis with threshold data
- Bayesian analysis example: gender of a random sample of people
- Informed prior
- Simulating a Bayesian inference calculation
- Hyperparameters
- Hyperparameter example: Micro-fractures on turbine blades
- Constructing a Bayesian inference posterior distribution in Excel
- Bayesian analysis example: Tigers in the jungle
- Markov chain Monte Carlo (MCMC) simulation
- Introduction to Bayesian inference concepts
- Bayesian estimate of the mean of a Normal distribution with known standard deviation
- Bayesian estimate of the mean of a Normal distribution with unknown standard deviation
- Determining prior distributions for correlated parameters
- Improper priors
- The Jacobian transformation
- Subjective prior based on data
- Taylor series approximation to a Bayesian posterior distribution
- Bayesian analysis example: The Monty Hall problem
- Determining prior distributions for uncorrelated parameters
- Subjective priors
- Normal approximation to the Beta posterior distribution
- Bayesian analysis example: identifying a weighted coin
- Bayesian estimate of the standard deviation of a Normal distribution with known mean
- Likelihood functions
- Bayesian estimate of the standard deviation of a Normal distribution with unknown mean
- Determining a prior distribution for a single parameter estimate
- Simulating from a constructed posterior distribution
- Bootstrap
- Comparison of Classical and Bayesian methods
- Analyzing and using data introduction
- Data Object
- Vose probability calculation
- Bayesian model averaging
- Miscellaneous
- Excel and ModelRisk model design and validation techniques
- Using range names for model clarity
- Color coding models for clarity
- Compare with known answers
- Checking units propagate correctly
- Stressing parameter values
- Model Validation and behavior introduction
- Informal auditing
- Analyzing outputs
- View random scenarios on screen and check for credibility
- Split up complex formulas (megaformulas)
- Building models that are efficient
- Comparing predictions against reality
- Numerical integration
- Comparing results of alternative models
- Building models that are easy to check and modify
- Model errors
- Model design introduction
- About array functions in Excel
- Excel and ModelRisk model design and validation techniques
- Monte Carlo simulation
- RISK ANALYSIS SOFTWARE
- Risk analysis software from Vose Software
- ModelRisk - risk modeling in Excel
- ModelRisk functions explained
- VoseCopulaOptimalFit and related functions
- VoseTimeOptimalFit and related functions
- VoseOptimalFit and related functions
- VoseXBounds
- VoseCLTSum
- VoseAggregateMoments
- VoseRawMoments
- VoseSkewness
- VoseMoments
- VoseKurtosis
- VoseAggregatePanjer
- VoseAggregateFFT
- VoseCombined
- VoseCopulaBiGumbel
- VoseCopulaBiClayton
- VoseCopulaBiNormal
- VoseCopulaBiT
- VoseKendallsTau
- VoseRiskEvent
- VoseCopulaBiFrank
- VoseCorrMatrix
- VoseRank
- VoseValidCorrmat
- VoseSpearman
- VoseCopulaData
- VoseCorrMatrixU
- VoseTimeSeasonalGBM
- VoseMarkovSample
- VoseMarkovMatrix
- VoseThielU
- VoseTimeEGARCH
- VoseTimeAPARCH
- VoseTimeARMA
- VoseTimeDeath
- VoseTimeAR1
- VoseTimeAR2
- VoseTimeARCH
- VoseTimeMA2
- VoseTimeGARCH
- VoseTimeGBMJDMR
- VoseTimePriceInflation
- VoseTimeGBMMR
- VoseTimeWageInflation
- VoseTimeLongTermInterestRate
- VoseTimeMA1
- VoseTimeGBM
- VoseTimeGBMJD
- VoseTimeShareYields
- VoseTimeYule
- VoseTimeShortTermInterestRate
- VoseDominance
- VoseLargest
- VoseSmallest
- VoseShift
- VoseStopSum
- VoseEigenValues
- VosePrincipleEsscher
- VoseAggregateMultiFFT
- VosePrincipleEV
- VoseCopulaMultiNormal
- VoseRunoff
- VosePrincipleRA
- VoseSumProduct
- VosePrincipleStdev
- VosePoissonLambda
- VoseBinomialP
- VosePBounds
- VoseAIC
- VoseHQIC
- VoseSIC
- VoseOgive1
- VoseFrequency
- VoseOgive2
- VoseNBootStdev
- VoseNBoot
- VoseSimulate
- VoseNBootPaired
- VoseAggregateMC
- VoseMean
- VoseStDev
- VoseAggregateMultiMoments
- VoseDeduct
- VoseExpression
- VoseLargestSet
- VoseKthSmallest
- VoseSmallestSet
- VoseKthLargest
- VoseNBootCofV
- VoseNBootPercentile
- VoseExtremeRange
- VoseNBootKurt
- VoseCopulaMultiClayton
- VoseNBootMean
- VoseTangentPortfolio
- VoseNBootVariance
- VoseNBootSkewness
- VoseIntegrate
- VoseInterpolate
- VoseCopulaMultiGumbel
- VoseCopulaMultiT
- VoseAggregateMultiMC
- VoseCopulaMultiFrank
- VoseTimeMultiMA1
- VoseTimeMultiMA2
- VoseTimeMultiGBM
- VoseTimeMultBEKK
- VoseAggregateDePril
- VoseTimeMultiAR1
- VoseTimeWilkie
- VoseTimeDividends
- VoseTimeMultiAR2
- VoseRuinFlag
- VoseRuinTime
- VoseDepletionShortfall
- VoseDepletion
- VoseDepletionFlag
- VoseDepletionTime
- VosejProduct
- VoseCholesky
- VoseTimeSimulate
- VoseNBootSeries
- VosejkProduct
- VoseRuinSeverity
- VoseRuin
- VosejkSum
- VoseTimeDividendsA
- VoseRuinNPV
- VoseTruncData
- VoseSample
- VoseIdentity
- VoseCopulaSimulate
- VoseSortA
- VoseFrequencyCumulA
- VoseAggregateDeduct
- VoseMeanExcessP
- VoseProb10
- VoseSpearmanU
- VoseSortD
- VoseFrequencyCumulD
- VoseRuinMaxSeverity
- VoseMeanExcessX
- VoseRawMoment3
- VosejSum
- VoseRawMoment4
- VoseNBootMoments
- VoseVariance
- VoseTimeShortTermInterestRateA
- VoseTimeLongTermInterestRateA
- VoseProb
- VoseDescription
- VoseCofV
- VoseAggregateProduct
- VoseEigenVectors
- VoseTimeWageInflationA
- VoseRawMoment1
- VosejSumInf
- VoseRawMoment2
- VoseShuffle
- VoseRollingStats
- VoseSplice
- VoseTSEmpiricalFit
- VoseTimeShareYieldsA
- VoseParameters
- VoseAggregateTranche
- VoseCovToCorr
- VoseCorrToCov
- VoseLLH
- VoseTimeSMEThreePoint
- VoseDataObject
- VoseCopulaDataSeries
- VoseDataRow
- VoseDataMin
- VoseDataMax
- VoseTimeSME2Perc
- VoseTimeSMEUniform
- VoseTimeSMESaturation
- VoseOutput
- VoseInput
- VoseTimeSMEPoisson
- VoseTimeBMAObject
- VoseBMAObject
- VoseBMAProb10
- VoseBMAProb
- VoseCopulaBMA
- VoseCopulaBMAObject
- VoseTimeEmpiricalFit
- VoseTimeBMA
- VoseBMA
- VoseSimKurtosis
- VoseOptConstraintMin
- VoseSimProbability
- VoseCurrentSample
- VoseCurrentSim
- VoseLibAssumption
- VoseLibReference
- VoseSimMoments
- VoseOptConstraintMax
- VoseSimMean
- VoseOptDecisionContinuous
- VoseOptRequirementEquals
- VoseOptRequirementMax
- VoseOptRequirementMin
- VoseOptTargetMinimize
- VoseOptConstraintEquals
- VoseSimVariance
- VoseSimSkewness
- VoseSimTable
- VoseSimCofV
- VoseSimPercentile
- VoseSimStDev
- VoseOptTargetValue
- VoseOptTargetMaximize
- VoseOptDecisionDiscrete
- VoseSimMSE
- VoseMin
- VoseMin
- VoseOptDecisionList
- VoseOptDecisionBoolean
- VoseOptRequirementBetween
- VoseOptConstraintBetween
- VoseSimMax
- VoseSimSemiVariance
- VoseSimSemiStdev
- VoseSimMeanDeviation
- VoseSimMin
- VoseSimCVARp
- VoseSimCVARx
- VoseSimCorrelation
- VoseSimCorrelationMatrix
- VoseOptConstraintString
- VoseOptCVARx
- VoseOptCVARp
- VoseOptPercentile
- VoseSimValue
- VoseSimStop
- Precision Control Functions
- VoseAggregateDiscrete
- VoseTimeMultiGARCH
- VoseTimeGBMVR
- VoseTimeGBMAJ
- VoseTimeGBMAJVR
- VoseSID
- Generalized Pareto Distribution (GPD)
- Generalized Pareto Distribution (GPD) Equations
- Three-Point Estimate Distribution
- Three-Point Estimate Distribution Equations
- VoseCalibrate
- ModelRisk interfaces
- Integrate
- Data Viewer
- Stochastic Dominance
- Library
- Correlation Matrix
- Portfolio Optimization Model
- Common elements of ModelRisk interfaces
- Risk Event
- Extreme Values
- Select Distribution
- Combined Distribution
- Aggregate Panjer
- Interpolate
- View Function
- Find Function
- Deduct
- Ogive
- AtRISK model converter
- Aggregate Multi FFT
- Stop Sum
- Crystal Ball model converter
- Aggregate Monte Carlo
- Splicing Distributions
- Subject Matter Expert (SME) Time Series Forecasts
- Aggregate Multivariate Monte Carlo
- Ordinary Differential Equation tool
- Aggregate FFT
- More on Conversion
- Multivariate Copula
- Bivariate Copula
- Univariate Time Series
- Modeling expert opinion in ModelRisk
- Multivariate Time Series
- Sum Product
- Aggregate DePril
- Aggregate Discrete
- Expert
- ModelRisk introduction
- Building and running a simple example model
- Distributions in ModelRisk
- List of all ModelRisk functions
- Custom applications and macros
- ModelRisk functions explained
- Tamara - project risk analysis
- Introduction to Tamara project risk analysis software
- Launching Tamara
- Importing a schedule
- Assigning uncertainty to the amount of work in the project
- Assigning uncertainty to productivity levels in the project
- Adding risk events to the project schedule
- Adding cost uncertainty to the project schedule
- Saving the Tamara model
- Running a Monte Carlo simulation in Tamara
- Reviewing the simulation results in Tamara
- Using Tamara results for cost and financial risk analysis
- Creating, updating and distributing a Tamara report
- Tips for creating a schedule model suitable for Monte Carlo simulation
- Random number generator and sampling algorithms used in Tamara
- Probability distributions used in Tamara
- Correlation with project schedule risk analysis
- Pelican - enterprise risk management