The quality of a risk analysis
See also: Risk management introduction
Risk analyses are often of poor quality. They might also be very expensive, take a long time to complete and use up valuable human resources. In fact, the more complex and expensive a quantitative risk analysis is, the more likely it is to be of poor quality. Worst of all, the people making decisions on the results of these analyses have little if any idea of how bad they are. These are rather attention-grabbing sentences but this topic is small and you really should not to skip over it: it could save you a lot of heartache.
The reasons a risk analysis can be terrible
To give some motivation for this topic, let us look at some of the results of a survey we ran some years ago in a well-developed science-based area of risk analysis. The question appears in the title of each pane. Which results do you find most worrying?
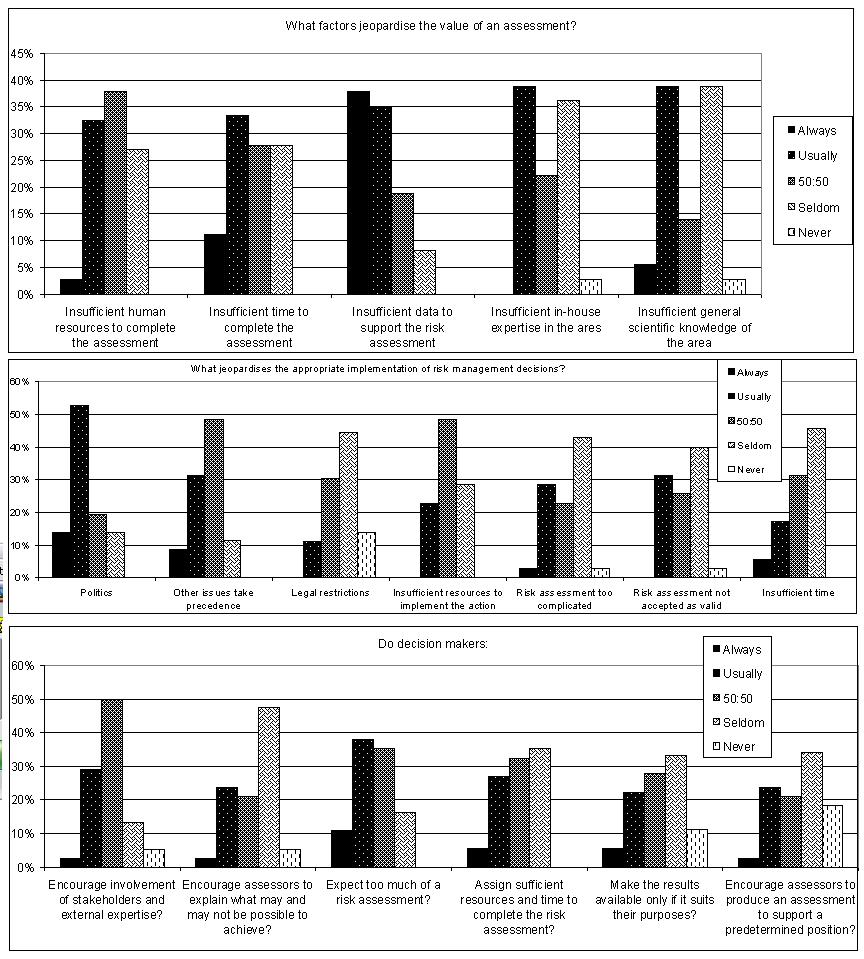
From the first of the figures above you'll see that there really needs to be more communication between decision-makers and their risk analysts and a greater attempt to work as a team. The risk analyst can be an important liaison between those 'on the ground' who understand the problem at hand and hold the data and those who make decisions. The risk analyst needs to understand the context of the decision question and have the flexibility to be able to find the method of analysis that gives the most useful information. Too often risk analysts complain that they get told to produce a quantitative model by the boss, but have to make the numbers up because the data aren't there. Now doesn't that seem silly? Surely the decision-maker would be none too happy to know the numbers are all made up, but the risk analyst is often not given access to the decision-makers to let them know. On the other hand, in some business and regulatory environments they are trying to follow a rule that says a quantitative risk analysis needs to be completed - the box needs ticking.
Regulations and guidelines can be a real impediment to creative thinking. Our founder, David Vose, has been in plenty of committees gathered to write risk analysis guidelines and he does his best to reverse the tendency to be formulaic. His argument is that in well over twenty years he have never done the same risk analysis twice: every one has its individual peculiarities. Risk analysis should not be a packaged commodity but a voyage of reasoned thinking leading to the best possible decision at the time.
It is usually pretty easy to see early on in the risk analysis process that a quantitative risk analysis will be of little value. There are several key areas where it can fall down:
-
It can't answer all the key questions;
-
There are going to be a lot of assumptions;
-
There is going to be one or more show-stopping assumption; and
-
There aren't enough good data or experts.
One can get around (1) sometimes by doing different risk analyses for different questions, but that can be problematic when each risk analysis has a different set of fundamental assumptions - how do we compare their results?
For (2) you need to have some way of expressing whether a lot of little assumptions compound to make a very vulnerable analysis: if you have 20 assumptions (and 20 is quite a small number), all pretty good ones - e.g. we think there's a 90% chance they are correct, but the analysis is only useful if all the assumptions are correct, then we only have a 0.920 = 12% chance that the assumption set is correct. Of course, if this was the real problem we wouldn't bother writing models. In reality, in the business world particularly, we deal with assumptions that are good enough because the answers we get are close enough. In some more scientific areas, like human health, we have to deal with assumptions like: compound X is present; compound X is toxic; people are exposed to compound X; the exposure is sufficient to cause harm; and treatment is ineffective. The sequence then produces the theoretical human harm we might want to protect against, but if any one of those assumptions is wrong there is no human health threat to worry about.
If (3) occurs we have a pretty good indication that we don't know enough to produce a decent risk analysis model, but maybe we can produce two or three crude models under different possible assumptions and see whether we come to the same conclusion anyway.
(4) is the least predictable area because the risk analyst doing a preliminary scoping can be reassured that the relevant data are available, but then finds out they are not available either because the data turn out to be clearly wrong (one sees this a lot, even in peer-reviewed work), the data aren't what was thought, there is a delay past the deadline in the data becoming available, or the data are dirty and need so much rework that it becomes impractical to analyze them within the decision timeframe.
There is a lot of emphasis placed on transparency in a risk analysis, which usually manifests itself in a large report describing the model, all the data and sources, the assumptions, etc. and then finishes with some graphical and numerical risk analysis outputs. I've seen reports of one or two hundred pages and that seem far from transparent to me - who really has the time or inclination to read such a document? The executive summary tends to focus on the decision question and numerical results, and places little emphasis on the robustness of the study.
Communicating quality of data
Elsewhere in this help file you will find lots of techniques for describing the numerical accuracy that a model can provide given the data that are available. These analyses are at the heart of a quantitative risk analysis and give us distributions, percentiles, sensitivity plots, etc.
We will now look at how to communicate any impact on the robustness of a model due to the assumptions behind using data or settling on a model scope and structure. We encourage the risk analyst to write down each assumption that is made in developing equations and performing statistical analyses.
We get participants to do the same in the training courses we teach as they solve simple class exercises and there is a general surprise at how many assumptions are implicit in even the simplest type of equations. It becomes rather onerous to write all these assumptions down, but it is even more difficult to convert the conceptual assumptions underpinning our probability models into something that a reader rather less familiar with probability modelling might understand.
The NUSAP method (Numeral Unit Spread Assessment Pedigree, Funtowicz and Ravetz, 1990) is a notational system that communicates the level of uncertainty for data in scientific analysis used for policy making. The idea is to use a number of experts in the field to score independently the data under different categories. The system is well-established as being useful in toxicological risk assessment. We describe here a generalization of the idea. It's key attractions are that it is easy to implement and can be summarised into consistent pictorial representations.
In the table below we used the categorisation descriptions of data from van der Sluijs et al (2005), which are: proxy - reflecting how close data being used are to ideal; empirical - reflecting the quantity and quality of the data; method - reflecting where the method used to collect the data lay between careful and well-established, and haphazard; and validation - reflecting whether the acquired data have been matched to real world experience (e.g. does an effect observed in a laboratory actually occur in the wider world).

Pedigree matrix for parameter strength (adapted from Boone et al, 2007).
Each data set is scored in turn by each expert. The average of all scores is calculated and then divided by the maximum attainable score of 4. For example:
|
|
Proxy |
Empirical |
Method |
Validation |
|
Expert A |
3 |
2 |
4 |
3 |
|
Expert B |
3 |
2 |
4 |
3 |
|
Expert C |
2 |
1 |
3 |
4 |
gives an average score of 2.833. Dividing by the maximum score of 4 gives 0.708. An additional level of sophistication is to allow the experts to weight their level of expertise for the particular variable in question (e.g. 0.3 for low, 0.6 for medium and 1.0 for high, as well as allowing experts to select not to make any comment when it is outside their competence) in which case one calculates a weighted average score. One can then plot these scores together and segregate them by different parts of the analysis if desired, which gives an overview of the robustness of data used in the analysis:
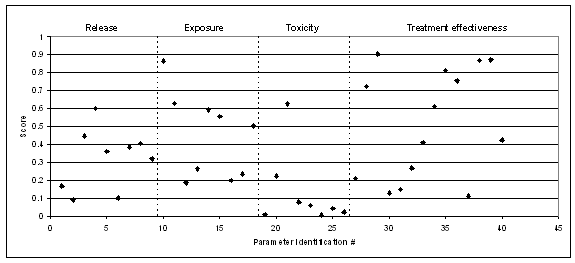
Plot of average scores for data sets in a toxicological risk assessment
Scores can be generally categorized as follows:
<0.2 weak
0.2 - 0.4 moderate
>0.4 - 0.8 high
>0.8 excellent
We can summarize the scores for each data set using a kite diagram to give a visual 'traffic light' green representing the parameter support is excellent, red representing weak, and one or two levels of orange representing gradations between these extremes. The figure below gives an example: one works from the centre point marking on the axes the weighted fraction of all the experts considering the parameter support to be 'excellent', then add the weighted fraction considering the support to be 'high' etc. These points are then joined to make the different color zones - from green in the centre for 'excellent', through yellow and orange, to red in the last category: a kite will be green if all experts agree the parameter support is excellent and red for weak.
Plotting these kite diagrams together can give a strong visual representation: a sea of green should give great confidence, a sea of red says the risk analysis is extremely weak. In practice, we'll end up with a big mix of colors but over time one can get a sense of what color mix is typical, when an analysis is comparatively weak or strong, and when it can be relied upon for your field.
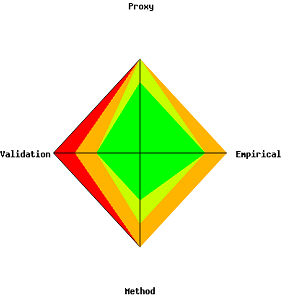
Summarizing the level of data support the experts believe that a model
parameter will have: red (dark) in the outer ban = weak; green (light)
in the inner band = excellent.
The only real impediment to using the system above is that you need to develop a database software tool. We have developed the Pelican risk management system for this purpose.
Level of criticality
The categorisation system described above helps determine whether a parameter is well-supported, but it can still misrepresent the robustness of the risk analysis. For example, we might have done a food safety microbial risk analysis involving ten parameters - nine enjoy high or excellent support, and one is suffering weak support. If that weakly supported parameter is defining the dose-response relationship (the probability a random individual will experience an adverse health effect given the number of pathogenic organisms ingested) then the whole risk analysis is jeopardized because the dose-response is the link between all the exposure pathways and the amount of pathogen involved (often a big model), and the size of human health impact that results. It is therefore rather useful to separate the kite diagrams and other analyses into different categories for the level of dependence the analysis has on each parameter: critical, important and small, for example.
A more sophisticated version for separating the level of dependence is to statistically analyze the degree of effect each parameter has on the numerical result: for example, one might look at the difference in the mean of the model output when the parameter distribution is replaced by its 95th and 5th percentile. Take that range and multiply by (1-the support score, giving 0 for excellent, 1 for terrible), gives one a sense of the level of vulnerability of the output numbers. However, this method suffers other problems. Imagine that we are performing a risk analysis on an emerging bacterium for which we have absolutely no dose-response data so we use a data set for a surrogate bacterium that we think will have a very similar effect (e.g. because it produces a similar toxin). We might have large amounts of excellent data for the surrogate bacterium and may therefore have little uncertainty about the dose-response model so using the 5th and 95th percentiles of the uncertainty about that dose-response model will result in a small change in the output and multiplying that by (1-the support score) will under-represent the real uncertainty. A second problem is that we often estimate two or more model parameters from the same data set: for example, a dose-response model often has two or three parameters that are fitted to data. Each parameter might be quite uncertain but the dose-response curve can be nonetheless quite stable, so this numerical analysis needs to look at the combined effect of the uncertain parameters as a single entity which requires a fair bit of number juggling.
The biggest uncertainty in a risk analysis
The techniques discussed above have focused on the vulnerability of the results of a risk analysis to the parameters of a model. When we are asked to review or audit a risk analysis the client is often surprised that our first step is not to look at the model mathematics and supporting statistical analyses, but to consider what the decision questions are, whether there were a number of assumptions, whether it would be possible to do the analysis a different (usually simpler, but sometimes more complex and precise) way, whether this other way would give the same answers and see if there are any means for comparing predictions against reality. What we are trying to do is see whether the structure and scope of the analysis is correct. The biggest uncertainty in a risk analysis is whether we started off analyzing the right thing and in the right way.
Finding the answer is very often not amenable to any numerical technique because we will not have any alternative to compare against. If we do, it might nonetheless take a great deal of effort to put together an alternative risk analysis model and a model audit is usually too late in the process to be able to start again. A much better idea, in my view, is to get a sense at the beginning of a risk analysis, on how confident we should be that the analysis will be scoped sufficiently broadly, or how confident we are that the world is adequately represented by our model. Needless to say, we can also start rather confident that our approach will be quite adequate and then, once having delved in to the details of the problem, find out we were quite mistaken so it is important to keep revisiting our view of the appropriateness of the model.
We encourage clients, particularly in the scientific areas of risk that we work in, to instigate a solid brainstorming session of experts and decision-makers whenever it has been decided that a risk analysis is to be undertaken, or maybe is just under consideration.
The focus is to discuss the form and scope of the potential risk analysis.
The experts first of all need to think about the decision-questions, discuss with decision-makers any possible alternatives or supplements to those questions and then consider how they can be answered, and what the outputs should look like (e.g. only the mean is required, or some high percentile). Each approach will have a set of assumptions which need to be thought through carefully: what would the effect be if the assumptions are wrong? If we use a conservative assumption and estimate a risk that is too high, are we back to where we started? We need to think about data requirements too: are the quality likely to be good and the data easily attainable?
When the brainstorming is over, we recommend that you pass around a questionnaire to each expert and ask those attending to independently answer a questionnaire something like this:
We discussed three risk analysis approaches (description A, description B, description C). Please indicate your level of confidence (0 = none, 1 = slight, 2 = good, 3 = excellent, -1 = no opinion) to the following:
-
What is your confidence that Method (A,...B,C) will be sufficiently flexible and comprehensive to answer any foreseeable questions from the management about this risk?
-
What is your confidence that Method (A,...B,C) is based on assumptions that are correct?
-
What is your confidence for Method (A,...B,C) that the necessary data will be available within the required timeframe and budget?
-
What is your confidence that the Method (A,...B,C) analysis will be completed in time?
-
What is your confidence that there will be strong support for Method (A,...B,C) among reviewing peers?
-
What is your confidence that there will be strong support for Method (A,...B,C) among stakeholders?
Asking each brainstorming participant independently will help you attain a balanced view, particularly if the chairperson of that meeting has enforced the discipline of requiring participants not to express their view on the above questions during the meeting (it won't be completely possible, but you are trying to make sure that nobody will be influenced into giving a desired answer). Asking people independently rather than trying to achieve consensus during the meeting will also help remove the over-confidence that often appears when people make a group decision.
Iterate
Things change. The political landscape in which the decision is to be made can become more hostile or accepting to some assumptions, data can prove better or worse than we initially thought, new data turn up, new questions suddenly become important, the time frame or budget can change, etc.
So it makes sense to go back from time to time over the types of assumptions analysis discussed above and to remain open to taking a different approach, even to making as dramatic a change as going from a quantitative to a qualitative risk analysis. That means you (analysts and decision makers alike) should also be a little guarded in making premature promises so you have some space to adapt. In our consultancy contracts, for example, a client will usually commission us to do a quantitative risk analysis and tell us about the data they have. We'll probably have had a little look at the data too. We prefer to structure our proposal into stages.
In the first stage we go over the decision problem, review any constraints and (time, money, political, etc.), take a first decent look at the available data, and figure out possible ways of getting to the answer. Then we produce a report describing how we want to tackle the problem and why. At that stage the client can stop the work, continue with us, do it themselves, or maybe hire someone else if they wish. It may take a little longer (usually a day or two) but everyone's expectations are kept realistic, we are not cornered into doing a risk analysis that we know is inappropriate, and clients don't waste their time or money. As consultants we are in the somewhat privileged position of turning down work that we know would be terrible. A risk analyst employed by a company or government department may not have that luxury.
Navigation
- Risk management
- Risk management introduction
- What are risks and opportunities?
- Planning a risk analysis
- Clearly stating risk management questions
- Evaluating risk management options
- Introduction to risk analysis
- The quality of a risk analysis
- Using risk analysis to make better decisions
- Explaining a models assumptions
- Statistical descriptions of model outputs
- Simulation Statistical Results
- Preparing a risk analysis report
- Graphical descriptions of model outputs
- Presenting and using results introduction
- Statistical descriptions of model results
- Mean deviation (MD)
- Range
- Semi-variance and semi-standard deviation
- Kurtosis (K)
- Mean
- Skewness (S)
- Conditional mean
- Custom simulation statistics table
- Mode
- Cumulative percentiles
- Median
- Relative positioning of mode median and mean
- Variance
- Standard deviation
- Inter-percentile range
- Normalized measures of spread - the CofV
- Graphical descriptionss of model results
- Showing probability ranges
- Overlaying histogram plots
- Scatter plots
- Effect of varying number of bars
- Sturges rule
- Relationship between cdf and density (histogram) plots
- Difficulty of interpreting the vertical scale
- Stochastic dominance tests
- Risk-return plots
- Second order cumulative probability plot
- Ascending and descending cumulative plots
- Tornado plot
- Box Plot
- Cumulative distribution function (cdf)
- Probability density function (pdf)
- Crude sensitivity analysis for identifying important input distributions
- Pareto Plot
- Trend plot
- Probability mass function (pmf)
- Overlaying cdf plots
- Cumulative Plot
- Simulation data table
- Statistics table
- Histogram Plot
- Spider plot
- Determining the width of histogram bars
- Plotting a variable with discrete and continuous elements
- Smoothing a histogram plot
- Risk analysis modeling techniques
- Monte Carlo simulation
- Monte Carlo simulation introduction
- Monte Carlo simulation in ModelRisk
- Filtering simulation results
- Output/Input Window
- Simulation Progress control
- Running multiple simulations
- Random number generation in ModelRisk
- Random sampling from input distributions
- How many Monte Carlo samples are enough?
- Probability distributions
- Distributions introduction
- Probability calculations in ModelRisk
- Selecting the appropriate distributions for your model
- List of distributions by category
- Distribution functions and the U parameter
- Univariate continuous distributions
- Beta distribution
- Beta Subjective distribution
- Four-parameter Beta distribution
- Bradford distribution
- Burr distribution
- Cauchy distribution
- Chi distribution
- Chi Squared distribution
- Continuous distributions introduction
- Continuous fitted distribution
- Cumulative ascending distribution
- Cumulative descending distribution
- Dagum distribution
- Erlang distribution
- Error distribution
- Error function distribution
- Exponential distribution
- Exponential family of distributions
- Extreme Value Minimum distribution
- Extreme Value Maximum distribution
- F distribution
- Fatigue Life distribution
- Gamma distribution
- Generalized Extreme Value distribution
- Generalized Logistic distribution
- Generalized Trapezoid Uniform (GTU) distribution
- Histogram distribution
- Hyperbolic-Secant distribution
- Inverse Gaussian distribution
- Johnson Bounded distribution
- Johnson Unbounded distribution
- Kernel Continuous Unbounded distribution
- Kumaraswamy distribution
- Kumaraswamy Four-parameter distribution
- Laplace distribution
- Levy distribution
- Lifetime Two-Parameter distribution
- Lifetime Three-Parameter distribution
- Lifetime Exponential distribution
- LogGamma distribution
- Logistic distribution
- LogLaplace distribution
- LogLogistic distribution
- LogLogistic Alternative parameter distribution
- LogNormal distribution
- LogNormal Alternative-parameter distribution
- LogNormal base B distribution
- LogNormal base E distribution
- LogTriangle distribution
- LogUniform distribution
- Noncentral Chi squared distribution
- Noncentral F distribution
- Normal distribution
- Normal distribution with alternative parameters
- Maxwell distribution
- Normal Mix distribution
- Relative distribution
- Ogive distribution
- Pareto (first kind) distribution
- Pareto (second kind) distribution
- Pearson Type 5 distribution
- Pearson Type 6 distribution
- Modified PERT distribution
- PERT distribution
- PERT Alternative-parameter distribution
- Reciprocal distribution
- Rayleigh distribution
- Skew Normal distribution
- Slash distribution
- SplitTriangle distribution
- Student-t distribution
- Three-parameter Student distribution
- Triangle distribution
- Triangle Alternative-parameter distribution
- Uniform distribution
- Weibull distribution
- Weibull Alternative-parameter distribution
- Three-Parameter Weibull distribution
- Univariate discrete distributions
- Discrete distributions introduction
- Bernoulli distribution
- Beta-Binomial distribution
- Beta-Geometric distribution
- Beta-Negative Binomial distribution
- Binomial distribution
- Burnt Finger Poisson distribution
- Delaporte distribution
- Discrete distribution
- Discrete Fitted distribution
- Discrete Uniform distribution
- Geometric distribution
- HypergeoM distribution
- Hypergeometric distribution
- HypergeoD distribution
- Inverse Hypergeometric distribution
- Logarithmic distribution
- Negative Binomial distribution
- Poisson distribution
- Poisson Uniform distribution
- Polya distribution
- Skellam distribution
- Step Uniform distribution
- Zero-modified counting distributions
- More on probability distributions
- Multivariate distributions
- Multivariate distributions introduction
- Dirichlet distribution
- Multinomial distribution
- Multivariate Hypergeometric distribution
- Multivariate Inverse Hypergeometric distribution type2
- Negative Multinomial distribution type 1
- Negative Multinomial distribution type 2
- Multivariate Inverse Hypergeometric distribution type1
- Multivariate Normal distribution
- More on probability distributions
- Approximating one distribution with another
- Approximations to the Inverse Hypergeometric Distribution
- Normal approximation to the Gamma Distribution
- Normal approximation to the Poisson Distribution
- Approximations to the Hypergeometric Distribution
- Stirlings formula for factorials
- Normal approximation to the Beta Distribution
- Approximation of one distribution with another
- Approximations to the Negative Binomial Distribution
- Normal approximation to the Student-t Distribution
- Approximations to the Binomial Distribution
- Normal_approximation_to_the_Binomial_distribution
- Poisson_approximation_to_the_Binomial_distribution
- Normal approximation to the Chi Squared Distribution
- Recursive formulas for discrete distributions
- Normal approximation to the Lognormal Distribution
- Normal approximations to other distributions
- Approximating one distribution with another
- Correlation modeling in risk analysis
- Common mistakes when adapting spreadsheet models for risk analysis
- More advanced risk analysis methods
- SIDs
- Modeling with objects
- ModelRisk database connectivity functions
- PK/PD modeling
- Value of information techniques
- Simulating with ordinary differential equations (ODEs)
- Optimization of stochastic models
- ModelRisk optimization extension introduction
- Optimization Settings
- Defining Simulation Requirements in an Optimization Model
- Defining Decision Constraints in an Optimization Model
- Optimization Progress control
- Defining Targets in an Optimization Model
- Defining Decision Variables in an Optimization Model
- Optimization Results
- Summing random variables
- Aggregate distributions introduction
- Aggregate modeling - Panjer's recursive method
- Adding correlation in aggregate calculations
- Sum of a random number of random variables
- Moments of an aggregate distribution
- Aggregate modeling in ModelRisk
- Aggregate modeling - Fast Fourier Transform (FFT) method
- How many random variables add up to a fixed total
- Aggregate modeling - compound Poisson approximation
- Aggregate modeling - De Pril's recursive method
- Testing and modeling causal relationships
- Stochastic time series
- Time series introduction
- Time series in ModelRisk
- Autoregressive models
- Thiel inequality coefficient
- Effect of an intervention at some uncertain point in time
- Log return of a Time Series
- Markov Chain models
- Seasonal time series
- Bounded random walk
- Time series modeling in finance
- Birth and death models
- Time series models with leading indicators
- Geometric Brownian Motion models
- Time series projection of events occurring randomly in time
- Simulation for six sigma
- ModelRisk's Six Sigma functions
- VoseSixSigmaCp
- VoseSixSigmaCpkLower
- VoseSixSigmaProbDefectShift
- VoseSixSigmaLowerBound
- VoseSixSigmaK
- VoseSixSigmaDefectShiftPPMUpper
- VoseSixSigmaDefectShiftPPMLower
- VoseSixSigmaDefectShiftPPM
- VoseSixSigmaCpm
- VoseSixSigmaSigmaLevel
- VoseSixSigmaCpkUpper
- VoseSixSigmaCpk
- VoseSixSigmaDefectPPM
- VoseSixSigmaProbDefectShiftLower
- VoseSixSigmaProbDefectShiftUpper
- VoseSixSigmaYield
- VoseSixSigmaUpperBound
- VoseSixSigmaZupper
- VoseSixSigmaZmin
- VoseSixSigmaZlower
- Modeling expert opinion
- Modeling expert opinion introduction
- Sources of error in subjective estimation
- Disaggregation
- Distributions used in modeling expert opinion
- A subjective estimate of a discrete quantity
- Incorporating differences in expert opinions
- Modeling opinion of a variable that covers several orders of magnitude
- Maximum entropy
- Probability theory and statistics
- Probability theory and statistics introduction
- Stochastic processes
- Stochastic processes introduction
- Poisson process
- Hypergeometric process
- The hypergeometric process
- Number in a sample with a particular characteristic in a hypergeometric process
- Number of hypergeometric samples to get a specific number of successes
- Number of samples taken to have an observed s in a hypergeometric process
- Estimate of population and sub-population sizes in a hypergeometric process
- The binomial process
- Renewal processes
- Mixture processes
- Martingales
- Estimating model parameters from data
- The basics
- Probability equations
- Probability theorems and useful concepts
- Probability parameters
- Probability rules and diagrams
- The definition of probability
- The basics of probability theory introduction
- Fitting probability models to data
- Fitting time series models to data
- Fitting correlation structures to data
- Fitting in ModelRisk
- Fitting probability distributions to data
- Fitting distributions to data
- Method of Moments (MoM)
- Check the quality of your data
- Kolmogorov-Smirnoff (K-S) Statistic
- Anderson-Darling (A-D) Statistic
- Goodness of fit statistics
- The Chi-Squared Goodness-of-Fit Statistic
- Determining the joint uncertainty distribution for parameters of a distribution
- Using Method of Moments with the Bootstrap
- Maximum Likelihood Estimates (MLEs)
- Fitting a distribution to truncated censored or binned data
- Critical Values and Confidence Intervals for Goodness-of-Fit Statistics
- Matching the properties of the variable and distribution
- Transforming discrete data before performing a parametric distribution fit
- Does a parametric distribution exist that is well known to fit this type of variable?
- Censored data
- Fitting a continuous non-parametric second-order distribution to data
- Goodness of Fit Plots
- Fitting a second order Normal distribution to data
- Using Goodness-of Fit Statistics to optimize Distribution Fitting
- Information criteria - SIC HQIC and AIC
- Fitting a second order parametric distribution to observed data
- Fitting a distribution for a continuous variable
- Does the random variable follow a stochastic process with a well-known model?
- Fitting a distribution for a discrete variable
- Fitting a discrete non-parametric second-order distribution to data
- Fitting a continuous non-parametric first-order distribution to data
- Fitting a first order parametric distribution to observed data
- Fitting a discrete non-parametric first-order distribution to data
- Fitting distributions to data
- Technical subjects
- Comparison of Classical and Bayesian methods
- Comparison of classic and Bayesian estimate of Normal distribution parameters
- Comparison of classic and Bayesian estimate of intensity lambda in a Poisson process
- Comparison of classic and Bayesian estimate of probability p in a binomial process
- Which technique should you use?
- Comparison of classic and Bayesian estimate of mean "time" beta in a Poisson process
- Classical statistics
- Bayesian
- Bootstrap
- The Bootstrap
- Linear regression parametric Bootstrap
- The Jackknife
- Multiple variables Bootstrap Example 2: Difference between two population means
- Linear regression non-parametric Bootstrap
- The parametric Bootstrap
- Bootstrap estimate of prevalence
- Estimating parameters for multiple variables
- Example: Parametric Bootstrap estimate of the mean of a Normal distribution with known standard deviation
- The non-parametric Bootstrap
- Example: Parametric Bootstrap estimate of mean number of calls per hour at a telephone exchange
- The Bootstrap likelihood function for Bayesian inference
- Multiple variables Bootstrap Example 1: Estimate of regression parameters
- Bayesian inference
- Uninformed priors
- Conjugate priors
- Prior distributions
- Bayesian analysis with threshold data
- Bayesian analysis example: gender of a random sample of people
- Informed prior
- Simulating a Bayesian inference calculation
- Hyperparameters
- Hyperparameter example: Micro-fractures on turbine blades
- Constructing a Bayesian inference posterior distribution in Excel
- Bayesian analysis example: Tigers in the jungle
- Markov chain Monte Carlo (MCMC) simulation
- Introduction to Bayesian inference concepts
- Bayesian estimate of the mean of a Normal distribution with known standard deviation
- Bayesian estimate of the mean of a Normal distribution with unknown standard deviation
- Determining prior distributions for correlated parameters
- Improper priors
- The Jacobian transformation
- Subjective prior based on data
- Taylor series approximation to a Bayesian posterior distribution
- Bayesian analysis example: The Monty Hall problem
- Determining prior distributions for uncorrelated parameters
- Subjective priors
- Normal approximation to the Beta posterior distribution
- Bayesian analysis example: identifying a weighted coin
- Bayesian estimate of the standard deviation of a Normal distribution with known mean
- Likelihood functions
- Bayesian estimate of the standard deviation of a Normal distribution with unknown mean
- Determining a prior distribution for a single parameter estimate
- Simulating from a constructed posterior distribution
- Bootstrap
- Comparison of Classical and Bayesian methods
- Analyzing and using data introduction
- Data Object
- Vose probability calculation
- Bayesian model averaging
- Miscellaneous
- Excel and ModelRisk model design and validation techniques
- Using range names for model clarity
- Color coding models for clarity
- Compare with known answers
- Checking units propagate correctly
- Stressing parameter values
- Model Validation and behavior introduction
- Informal auditing
- Analyzing outputs
- View random scenarios on screen and check for credibility
- Split up complex formulas (megaformulas)
- Building models that are efficient
- Comparing predictions against reality
- Numerical integration
- Comparing results of alternative models
- Building models that are easy to check and modify
- Model errors
- Model design introduction
- About array functions in Excel
- Excel and ModelRisk model design and validation techniques
- Monte Carlo simulation
- RISK ANALYSIS SOFTWARE
- Risk analysis software from Vose Software
- ModelRisk - risk modeling in Excel
- ModelRisk functions explained
- VoseCopulaOptimalFit and related functions
- VoseTimeOptimalFit and related functions
- VoseOptimalFit and related functions
- VoseXBounds
- VoseCLTSum
- VoseAggregateMoments
- VoseRawMoments
- VoseSkewness
- VoseMoments
- VoseKurtosis
- VoseAggregatePanjer
- VoseAggregateFFT
- VoseCombined
- VoseCopulaBiGumbel
- VoseCopulaBiClayton
- VoseCopulaBiNormal
- VoseCopulaBiT
- VoseKendallsTau
- VoseRiskEvent
- VoseCopulaBiFrank
- VoseCorrMatrix
- VoseRank
- VoseValidCorrmat
- VoseSpearman
- VoseCopulaData
- VoseCorrMatrixU
- VoseTimeSeasonalGBM
- VoseMarkovSample
- VoseMarkovMatrix
- VoseThielU
- VoseTimeEGARCH
- VoseTimeAPARCH
- VoseTimeARMA
- VoseTimeDeath
- VoseTimeAR1
- VoseTimeAR2
- VoseTimeARCH
- VoseTimeMA2
- VoseTimeGARCH
- VoseTimeGBMJDMR
- VoseTimePriceInflation
- VoseTimeGBMMR
- VoseTimeWageInflation
- VoseTimeLongTermInterestRate
- VoseTimeMA1
- VoseTimeGBM
- VoseTimeGBMJD
- VoseTimeShareYields
- VoseTimeYule
- VoseTimeShortTermInterestRate
- VoseDominance
- VoseLargest
- VoseSmallest
- VoseShift
- VoseStopSum
- VoseEigenValues
- VosePrincipleEsscher
- VoseAggregateMultiFFT
- VosePrincipleEV
- VoseCopulaMultiNormal
- VoseRunoff
- VosePrincipleRA
- VoseSumProduct
- VosePrincipleStdev
- VosePoissonLambda
- VoseBinomialP
- VosePBounds
- VoseAIC
- VoseHQIC
- VoseSIC
- VoseOgive1
- VoseFrequency
- VoseOgive2
- VoseNBootStdev
- VoseNBoot
- VoseSimulate
- VoseNBootPaired
- VoseAggregateMC
- VoseMean
- VoseStDev
- VoseAggregateMultiMoments
- VoseDeduct
- VoseExpression
- VoseLargestSet
- VoseKthSmallest
- VoseSmallestSet
- VoseKthLargest
- VoseNBootCofV
- VoseNBootPercentile
- VoseExtremeRange
- VoseNBootKurt
- VoseCopulaMultiClayton
- VoseNBootMean
- VoseTangentPortfolio
- VoseNBootVariance
- VoseNBootSkewness
- VoseIntegrate
- VoseInterpolate
- VoseCopulaMultiGumbel
- VoseCopulaMultiT
- VoseAggregateMultiMC
- VoseCopulaMultiFrank
- VoseTimeMultiMA1
- VoseTimeMultiMA2
- VoseTimeMultiGBM
- VoseTimeMultBEKK
- VoseAggregateDePril
- VoseTimeMultiAR1
- VoseTimeWilkie
- VoseTimeDividends
- VoseTimeMultiAR2
- VoseRuinFlag
- VoseRuinTime
- VoseDepletionShortfall
- VoseDepletion
- VoseDepletionFlag
- VoseDepletionTime
- VosejProduct
- VoseCholesky
- VoseTimeSimulate
- VoseNBootSeries
- VosejkProduct
- VoseRuinSeverity
- VoseRuin
- VosejkSum
- VoseTimeDividendsA
- VoseRuinNPV
- VoseTruncData
- VoseSample
- VoseIdentity
- VoseCopulaSimulate
- VoseSortA
- VoseFrequencyCumulA
- VoseAggregateDeduct
- VoseMeanExcessP
- VoseProb10
- VoseSpearmanU
- VoseSortD
- VoseFrequencyCumulD
- VoseRuinMaxSeverity
- VoseMeanExcessX
- VoseRawMoment3
- VosejSum
- VoseRawMoment4
- VoseNBootMoments
- VoseVariance
- VoseTimeShortTermInterestRateA
- VoseTimeLongTermInterestRateA
- VoseProb
- VoseDescription
- VoseCofV
- VoseAggregateProduct
- VoseEigenVectors
- VoseTimeWageInflationA
- VoseRawMoment1
- VosejSumInf
- VoseRawMoment2
- VoseShuffle
- VoseRollingStats
- VoseSplice
- VoseTSEmpiricalFit
- VoseTimeShareYieldsA
- VoseParameters
- VoseAggregateTranche
- VoseCovToCorr
- VoseCorrToCov
- VoseLLH
- VoseTimeSMEThreePoint
- VoseDataObject
- VoseCopulaDataSeries
- VoseDataRow
- VoseDataMin
- VoseDataMax
- VoseTimeSME2Perc
- VoseTimeSMEUniform
- VoseTimeSMESaturation
- VoseOutput
- VoseInput
- VoseTimeSMEPoisson
- VoseTimeBMAObject
- VoseBMAObject
- VoseBMAProb10
- VoseBMAProb
- VoseCopulaBMA
- VoseCopulaBMAObject
- VoseTimeEmpiricalFit
- VoseTimeBMA
- VoseBMA
- VoseSimKurtosis
- VoseOptConstraintMin
- VoseSimProbability
- VoseCurrentSample
- VoseCurrentSim
- VoseLibAssumption
- VoseLibReference
- VoseSimMoments
- VoseOptConstraintMax
- VoseSimMean
- VoseOptDecisionContinuous
- VoseOptRequirementEquals
- VoseOptRequirementMax
- VoseOptRequirementMin
- VoseOptTargetMinimize
- VoseOptConstraintEquals
- VoseSimVariance
- VoseSimSkewness
- VoseSimTable
- VoseSimCofV
- VoseSimPercentile
- VoseSimStDev
- VoseOptTargetValue
- VoseOptTargetMaximize
- VoseOptDecisionDiscrete
- VoseSimMSE
- VoseMin
- VoseMin
- VoseOptDecisionList
- VoseOptDecisionBoolean
- VoseOptRequirementBetween
- VoseOptConstraintBetween
- VoseSimMax
- VoseSimSemiVariance
- VoseSimSemiStdev
- VoseSimMeanDeviation
- VoseSimMin
- VoseSimCVARp
- VoseSimCVARx
- VoseSimCorrelation
- VoseSimCorrelationMatrix
- VoseOptConstraintString
- VoseOptCVARx
- VoseOptCVARp
- VoseOptPercentile
- VoseSimValue
- VoseSimStop
- Precision Control Functions
- VoseAggregateDiscrete
- VoseTimeMultiGARCH
- VoseTimeGBMVR
- VoseTimeGBMAJ
- VoseTimeGBMAJVR
- VoseSID
- Generalized Pareto Distribution (GPD)
- Generalized Pareto Distribution (GPD) Equations
- Three-Point Estimate Distribution
- Three-Point Estimate Distribution Equations
- VoseCalibrate
- ModelRisk interfaces
- Integrate
- Data Viewer
- Stochastic Dominance
- Library
- Correlation Matrix
- Portfolio Optimization Model
- Common elements of ModelRisk interfaces
- Risk Event
- Extreme Values
- Select Distribution
- Combined Distribution
- Aggregate Panjer
- Interpolate
- View Function
- Find Function
- Deduct
- Ogive
- AtRISK model converter
- Aggregate Multi FFT
- Stop Sum
- Crystal Ball model converter
- Aggregate Monte Carlo
- Splicing Distributions
- Subject Matter Expert (SME) Time Series Forecasts
- Aggregate Multivariate Monte Carlo
- Ordinary Differential Equation tool
- Aggregate FFT
- More on Conversion
- Multivariate Copula
- Bivariate Copula
- Univariate Time Series
- Modeling expert opinion in ModelRisk
- Multivariate Time Series
- Sum Product
- Aggregate DePril
- Aggregate Discrete
- Expert
- ModelRisk introduction
- Building and running a simple example model
- Distributions in ModelRisk
- List of all ModelRisk functions
- Custom applications and macros
- ModelRisk functions explained
- Tamara - project risk analysis
- Introduction to Tamara project risk analysis software
- Launching Tamara
- Importing a schedule
- Assigning uncertainty to the amount of work in the project
- Assigning uncertainty to productivity levels in the project
- Adding risk events to the project schedule
- Adding cost uncertainty to the project schedule
- Saving the Tamara model
- Running a Monte Carlo simulation in Tamara
- Reviewing the simulation results in Tamara
- Using Tamara results for cost and financial risk analysis
- Creating, updating and distributing a Tamara report
- Tips for creating a schedule model suitable for Monte Carlo simulation
- Random number generator and sampling algorithms used in Tamara
- Probability distributions used in Tamara
- Correlation with project schedule risk analysis
- Pelican - enterprise risk management