Monte Carlo Simulation
a Simple GuideWhat is Monte Carlo simulation?
Monte Carlo simulation (also known as the Monte Carlo Method) is a computer simulation technique that constructs probability distributions of the possible outcomes of the decisions you might choose to make. Creating the probability distributions of the outcomes allows the decision-maker to quantitatively assess the level of risk that comes with taking a particular decision and, as a result, select the decision that provides the best balance of benefit against risk.
A typical result of a Monte Carlo simulation is a histogram of the simulated outcomes, like the following:
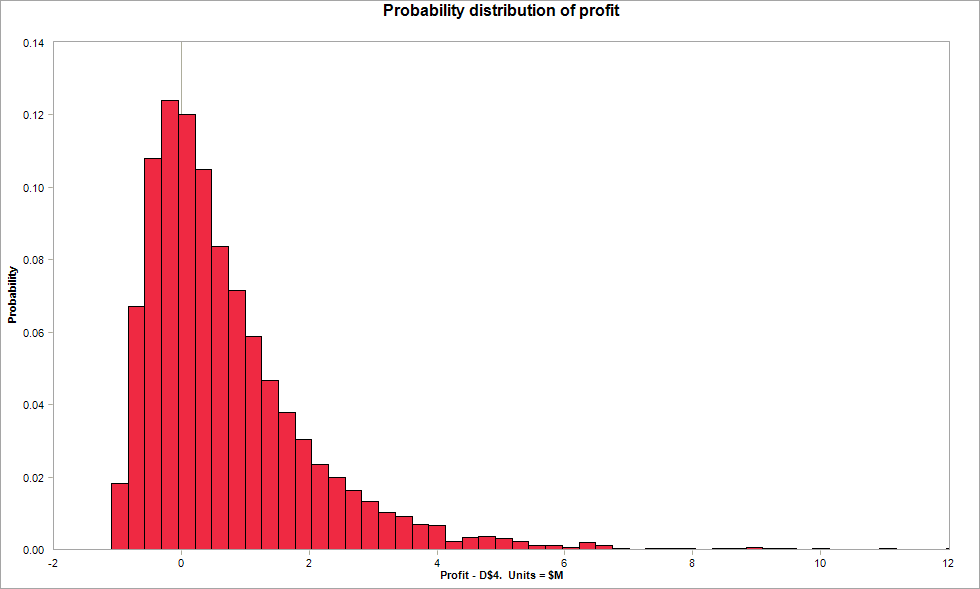
The horizontal axis shows the possible amount of profit a venture may make, and the vertical axis states how likely those values are. In this example, the histogram shows that the most likely profit is a little under zero, with a possible loss of up to $1M or so, but a potential gain of $5-6M, or even higher (though with a very small probability).

ModelRisk
Adding risk and uncertainty to your Excel model
ModelRisk is the world’s most innovative and comprehensive risk analysis add-in for Excel using Monte Carlo simulation. Use ModelRisk to describe uncertainty in your budget, financial model, sales forecast, or any other area you use Excel for.
How does a Monte Carlo simulation work?
To perform a Monte Carlo simulation, you must first have a mathematical model, like a spreadsheet. The model will have one of more results of interest (called outputs) - like profit, NPV, cashflow, cost, sales volume, etc. The model will depend on a number of quantitative assumptions (called inputs) - like market size, macroeconomic factors, production capacity, etc. Then for given values of these inputs, the model determines the value of the outputs through a series of equations.
The greatest weakness of such models is that we are almost always unsure what the value of the inputs will be and, as a result, we are unsure of the outputs.
Before Monte Carlo simulation, decision-makers would explore how uncertain the outputs (like profit) were by running different 'what-if' scenarios. In a typical what-if scenario, one would enter values for each input that would reduce the output result and note the drop in the output, then enter input values that would increase the output and again note the change in the output. This would give a feel for how uncertain the output value was. For example, the following model performs three what-if scenarios, summing a set of costs, where the three scenarios explore what the total cost (the output) might be if each individual cost item (the inputs) were all very low, all at values considered likely, or all at high values:
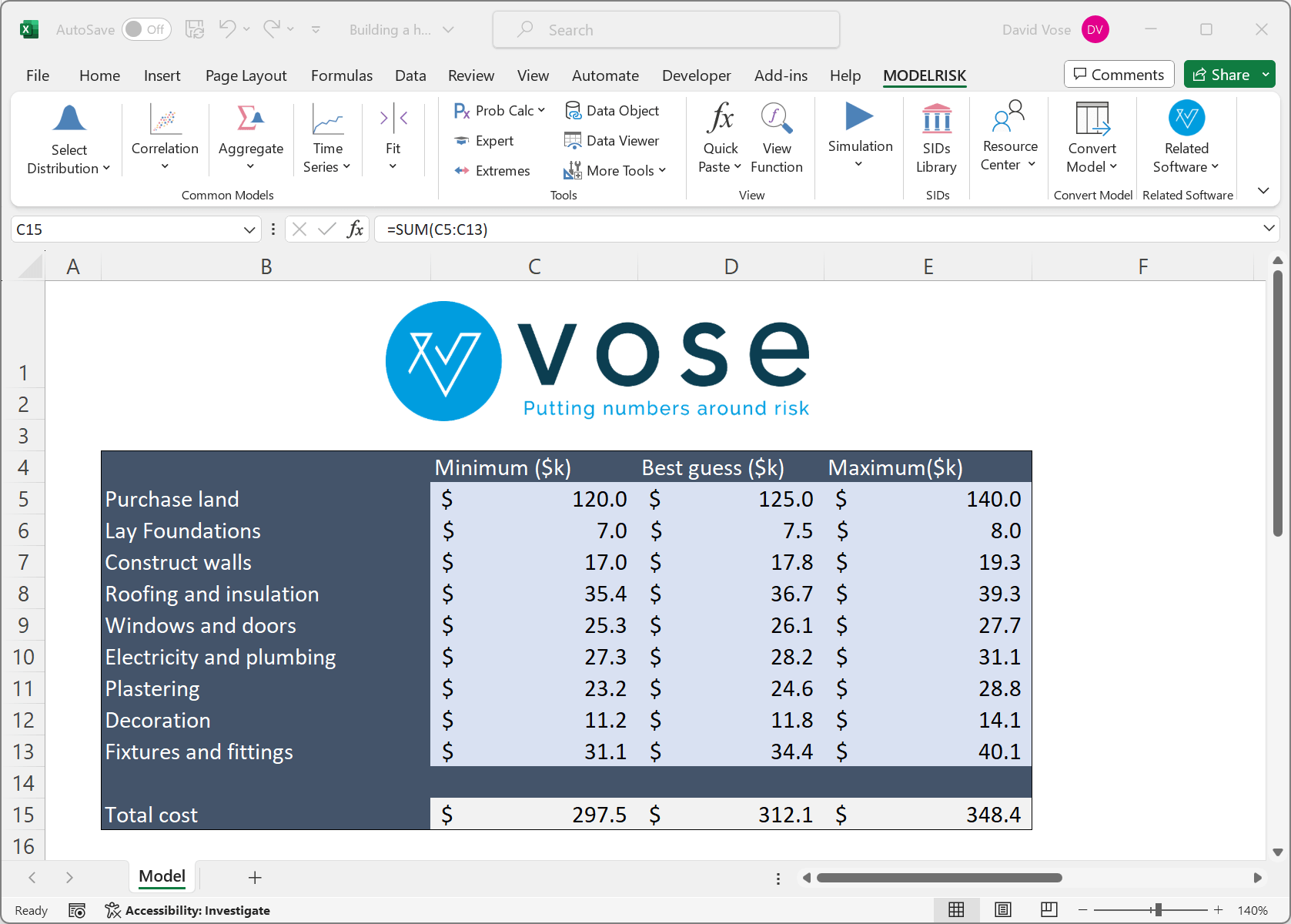
This kind of analysis shows the decision-maker that the total cost will lie somewhere between $297.5k and $348.4k, and projects a most likely cost of $312.1.
Although simple, these 'What-if' analyses are largely useless because of three key issues:
- They do not take account of the probability of a scenario. For example, if we could say that there was a 1% chance that each of the cost items was in the range of the minimum estimate then, assuming these costs were independent of each other, the chances of all lying around their minimum value would be 1% x 1% x ... x 1%, i..e 0.019 = 1 in a billion billion, a probability so small as to be meaningless.
- They don't consider the variety of values that an input can take, just two or three possible values; and
- They don't take account of the combinations of values that could constitute a scenario. For example, in the model above some costs could be towards their minima, others towards their maxima, and others around the best guess. With just these nine variables and three values per variable, one can construct 39, nearly 20,000 different combinations!
Monte Carlo simulation replaces the values for uncertain variables within the model with functions that generate random samples from probability distributions that represent the uncertainty. For example, the following model is written in ModelRisk:
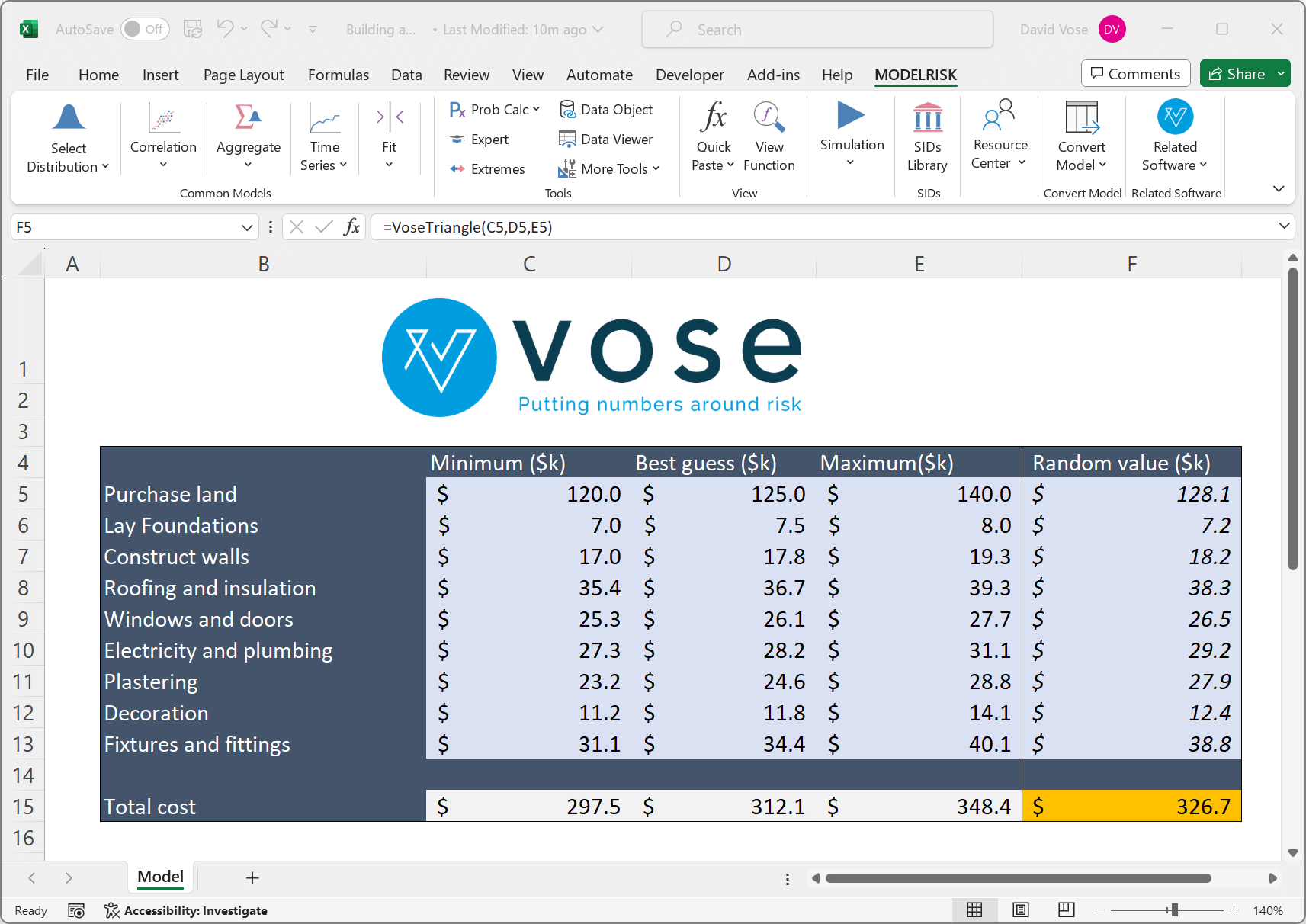
The Cell F5 contains the ModelRisk function VoseTriangle(Minimum, MostLikely, Maximum) where the input parameters come from the sheet. The function randomly generates a sample, here $128.1k, where the probability of each possible value being generated is defined by the shape of the distribution used. In this case, the Triangle(120, 125, 140) looks like this:
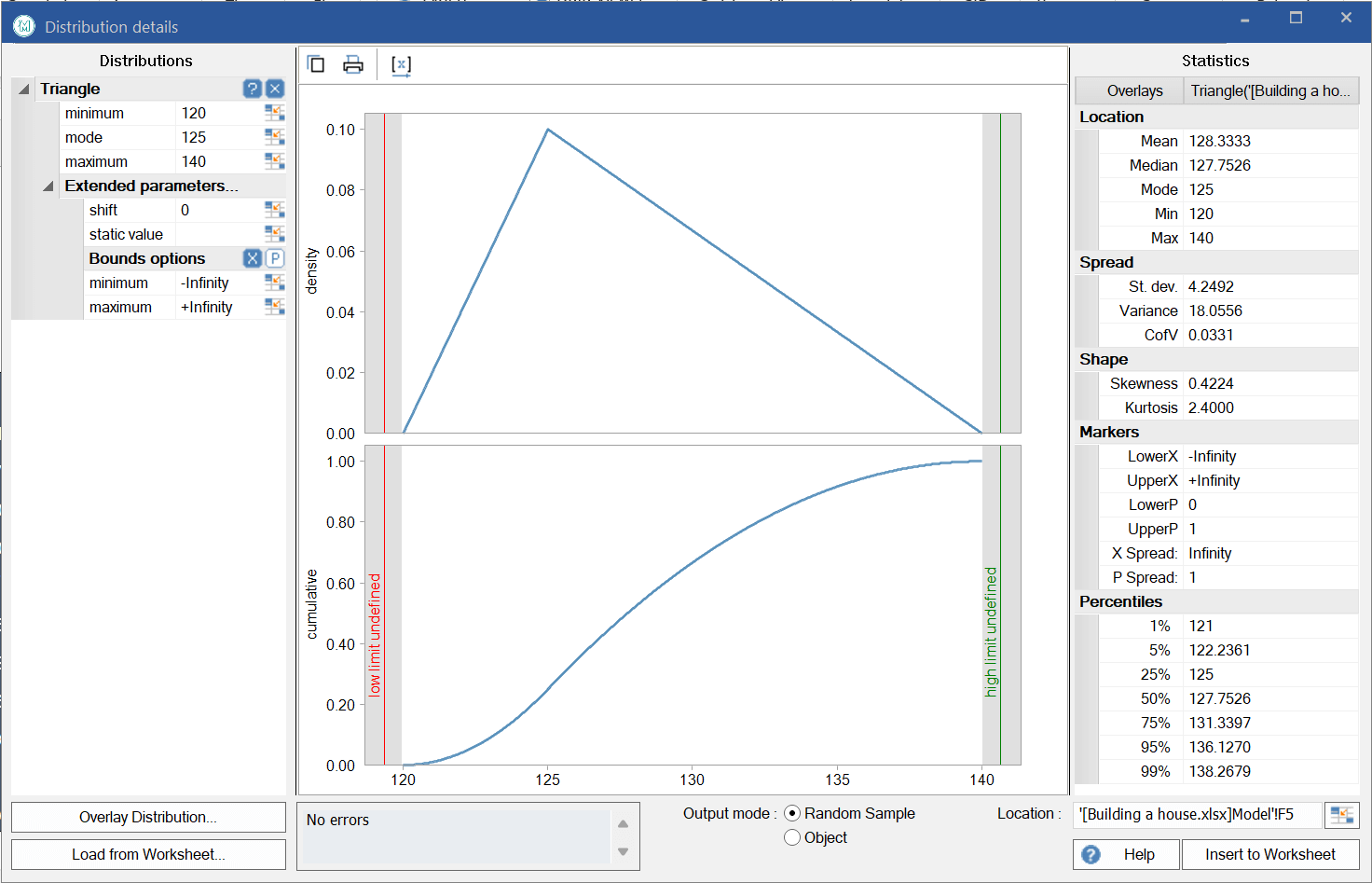
The horizontal axis represents the possible value of the variable (the land purchase cost) and the vertical axis represents the probability of each value occurring. The Triangle distribution interprets the three input values with straight lines to form a triangular shape, hence its name. There are many different distribution types used in risk analysis. The most common are: Triangle, PERT, binomial, Poisson, Normal, Lognormal and Uniform distributions. However, depending on the subject of the model (e.g. stock prices, system reliability, epidemiology) the set of distributions used will be very different. ModelRisk includes essentially all probability distributions used in risk analysis.
In a Monte Carlo simulation model, values that are uncertain are replaced by functions generating random samples from distributions chosen by the modeller. Then a simulation is run on that model, which amounts to recalculating the model many times, each time using different random values for all the uncertain variables and storing the resultant values for each output of the model. At the end of the simulation run, the values for each output can be analysed in various ways - graphs like the histogram above, and others, give pictorial representations of the shape and range of the uncertainty for each output. The output data can also be analysed statistically to provide information like the probability of the output falling above (or below) some specific target value.
How random samples are generated from uncertain variables
Every probability distribution can be represented by a cumulative distribution function, as shown below:
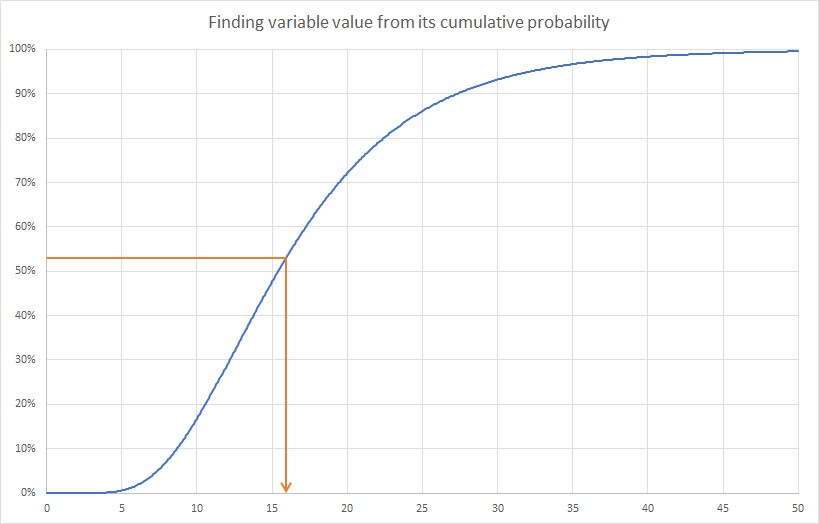
By definition, a random value from a probability distribution is equally likely to be at any cumulative probability. Reversing that logic, we can generate a random number for the variable by sampling from a Uniform distribution between 0 and 1, and then use the cumulative curve to translate this into a sample value for the variable. In the illustration above, a random value of 0.53 from the Uniform(0,1) distribution translates into a value of 15.9 for the variable.
Due to the shape of each cumulative curve, more values will be generated where the cumulative curve is at its steepest, as shown below:
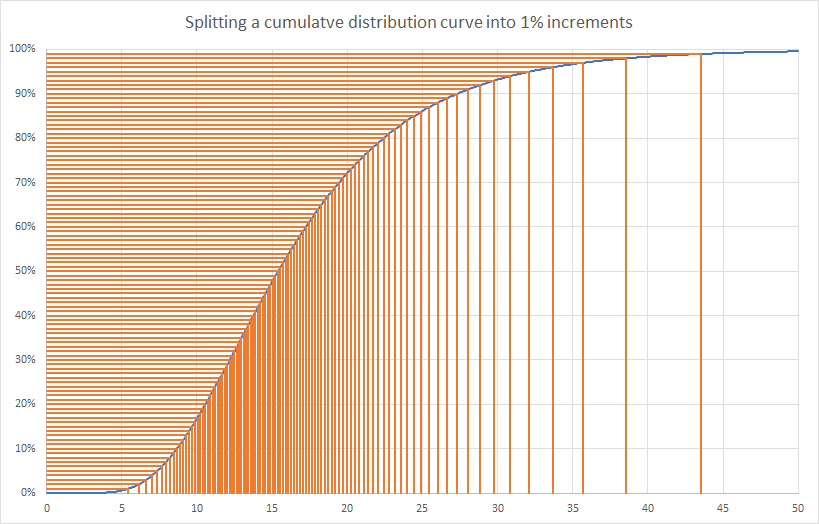
Key to Monte Carlo simulation is that values are generated with a frequency that is proportional to how likely they are to occur. We can then make a histogram distribution or cumulative distribution from the generated output results, and the resultant distributions can be interpreted as approximations to the true theoretical distributions of the output variables.
The more samples (sometimes called iterations) that are run in a simulation, the smoother the resultant distributions become and the more precisely they match the true theoretical result.
Random number generators used for Monte Carlo simulation
EEvery probability distribution can be represented by a cumulative distribution function, as shown below:
In order to produce a high quality Monte Carlo simulation, one must have a method of generating Uniform(0,1) random numbers. Vose Software simulation products uses the Mersenne Twister, which is widely considered as the best all-round algorithm. The algorithm uses the generated value as an input to produce the next value. The random number generating algorithm starts with a seed value, and all subsequent random numbers that are generated will rely on this initial seed value.
ModelRisk and Tamara both offer the possibility of specifying the seed value for a simulation, an integer from 1 to 2,147,483,647. . It is good practice always to use a seed value and to use the same numbers habitually (like 1, or your date of birth) as you will remember them in case you want to reproduce the same results exactly. Providing the model is not changed, the same simulation results can be exactly reproduced. More importantly, one or more distributions can be changed within the model and by running a second simulation one can look at the effect these changes have on the model's outputs. It is then certain that any observed change in the result is due to changes in the model and not a result of the randomness of the sampling.
The more samples (sometimes called iterations) that are run in a simulation, the smoother the resultant distributions become and the more precisely they match the true theoretical result.
How many samples to run in a Monte Carlo simulation
A very common question is how to determine how many samples to run in a Monte Carlo simulation, which is discussed here.